

VMware 已针对称为 Spring4Shell 的关键远程代码执行漏洞发布了安全更新,该漏洞影响了其多个云计算和虚拟化产品。
受 Spring4Shell 影响的 VMware 产品列表可从该公司的咨询中获得。在没有可用的修复程序的情况下,VMware 发布了一个解决方法作为临时解决方案。
此时,遵循安全公告中提供的建议至关重要,因为 Spring4Shell 是一个被积极利用的漏洞。
流行框架中的缺陷
Spring4Shell,官方编号为 CVE-2022-22965,是 Spring Core Java 框架中的一个远程代码执行漏洞,无需身份验证即可利用,严重性评分为 9.8(满分 10)。
这意味着任何有权访问易受攻击的应用程序的恶意行为者都可以执行任意命令并完全控制目标系统。
由于用于 Java 应用程序开发的 Spring Framework 的广泛部署,安全分析师担心利用 Spring4Shell 漏洞进行大规模攻击。
更糟糕的是,一个有效的概念验证 (PoC) 漏洞甚至在安全更新可用之前就在 GitHub 上泄露,从而增加了恶意利用和“意外”攻击的机会。
影响和补救
该严重缺陷影响在 JDK 9+ 上运行的 Spring MVC 和 Spring WebFlux 应用程序。该漏洞利用要求应用程序作为 WAR 部署在 Tomcat 上运行,尽管确切的限制仍在调查中。
应用程序的固定版本是:
Spring Framework 5.3.18 和 Spring Framework 5.2.20
春季启动 2.5.12
Spring Boot 2.6.6(即将发布)
VMWare 已审查其产品组合,虽然调查仍在继续,但已确定以下产品受到影响:
适用于 VM 的 VMware Tanzu 应用服务 – 版本 2.10 至 2.13
VMware Tanzu Operations Manager - 版本 2.8 到 2.9
VMware 子公司 Kubernetes 网格集成版 (TKGI) - 版本 1.11 到 1.13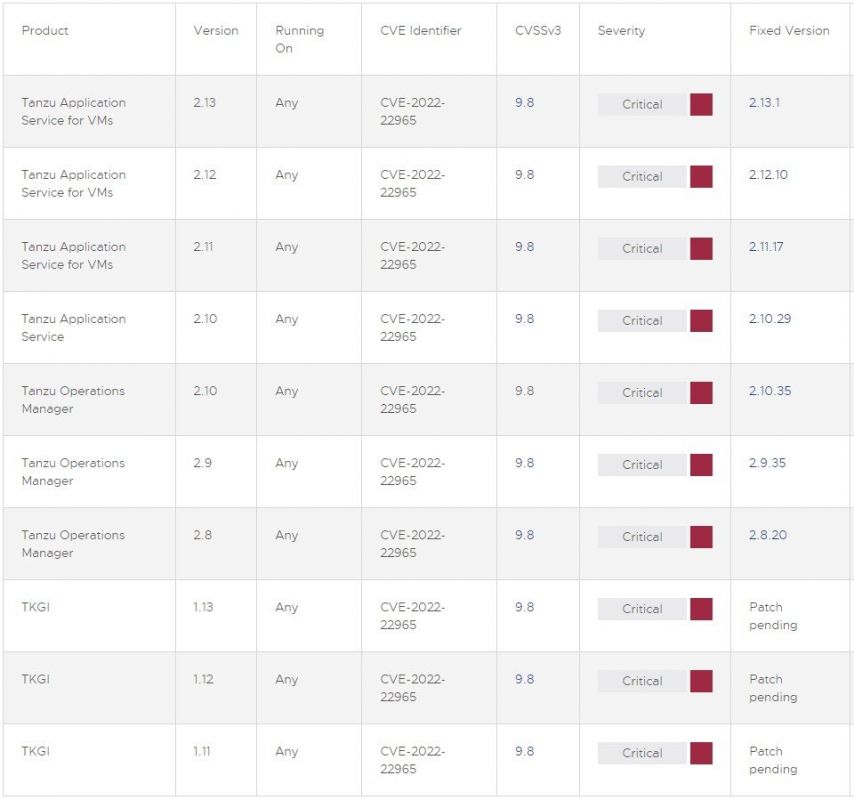
受影响产品及修复版本汇总 ( VMWare)
该供应商已经为前两个产品提供了可用的安全更新,涵盖多个版本分支和点发布,但 VMware Tanzu Kubernetes Grid Integrated Edition 的永久修复仍在进行中。
对于这些部署,VMWare 发布了解决方法说明 ,旨在帮助管理员在补丁发布之前临时保护他们的系统。
需要注意的一点是,VMWare 发现 TKGI 中的 Spring4Shell 漏洞利用很复杂,因此提供了缓解建议和即将推出的安全更新,以最大限度地提高客户信心并避免误报。
尽管如此,仍应遵循提供的官方安全建议,不得有任何偏差和延误,以确保您的部署不受机会主义威胁参与者的攻击。

GitHub 周一宣布,它为 GitHub Advanced Security 客户扩展了其代码托管平台的机密扫描功能,以自动阻止机密泄漏。
秘密扫描是一种高级安全选项,使用具有 GitHub 高级安全许可证的 GitHub Enterprise Cloud 的组织可以启用额外的存储库扫描。
它通过匹配由组织定义或由合作伙伴和服务提供商提供的模式来工作。每个匹配项都在存储库的安全选项卡中报告为安全警报,如果匹配合作伙伴模式,则报告给合作伙伴。
自动阻止意外机密泄露
新功能称为推送保护,旨在防止在将代码提交到远程存储库之前意外暴露凭据。
这项新功能将秘密扫描嵌入到开发人员的工作流程中,它 适用于 69 种令牌类型 (API 密钥、身份验证令牌、访问令牌、管理证书、凭证、私钥、密钥等),可检测到低“误报” “ 检测率。
“通过推送保护,GitHub 将在开发人员推送代码时检查高度可信的机密,并在发现机密时阻止推送,”GitHub表示。
“为了在不影响开发效率的情况下实现这一点,推送保护仅支持可以准确检测的令牌类型。”
如果 GitHub Enterprise Cloud 在推送代码之前识别出机密,则 git push 会被阻止,以允许开发人员查看并从他们尝试推送到远程存储库的代码中删除机密。
开发人员还可以将这些安全警报标记为误报、测试用例,或将它们标记为稍后修复。
如何启用秘密扫描推送保护
拥有 GitHub Advanced Security 的组织可以通过 API 或从用户界面一键在存储库和组织级别启用秘密扫描推送保护功能。
为您的组织启用推送保护的详细过程要求您:
在 GitHub.com 上,导航到组织的主页。
在您的组织名称下,单击 设置。
在侧边栏的“安全”部分,点击 代码安全和分析。
在“代码安全和分析”下,找到“GitHub 高级安全”。
在“推送保护”下的“秘密扫描”下,单击 全部启用。
或者,单击“自动启用添加到秘密扫描的私有存储库”。
您还可以通过从 repo 的 Settings > Security & analysis > GitHub Advanced Security 对话框打开它来为单个存储库启用它。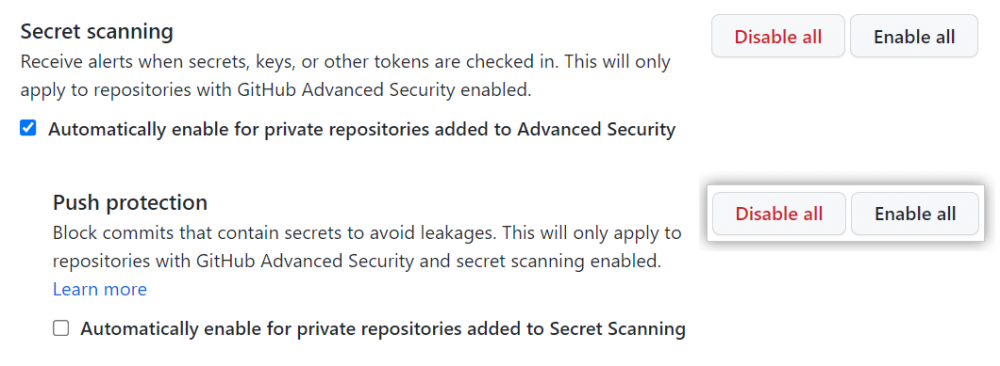
启用 GitHub 秘密扫描推送保护 (GitHub)
您可以从此处找到有关秘密扫描功能的更多信息,以及有关如何从命令行使用推送保护或允许从此处推送某些秘密的更多详细信息。
“迄今为止,GitHub 已经使用 GitHub Advanced Security 的秘密扫描在数千个私有存储库中检测到超过 700,000 个秘密;GitHub 还扫描所有公共存储库中的合作伙伴模式(免费),”GitHub 补充道。
“今天,我们正在为 GitHub 高级安全客户添加选项,以通过在 git push 被接受之前扫描机密来完全防止泄漏发生。”
正如 BleepingComputer 先前报道的 [ 1 , 2 , 3 ],暴露的凭据和机密已导致高影响力的违规行为。
因此,在提交代码之前启用自动机密扫描将使组织更接近于保护自己免受意外泄漏和提高供应链安全性。
AMD 宣布收购 Pensando Systems,该公司开发 DPU——用于提供网络管理、安全和数据存储的服务器的硬件加速器。该交易价值19亿美元。
Pensando 联合创始人兼首席技术官 Vipin Jain 最近告诉The Register,该公司渴望成为“基础设施领域的 Nvidia”,通过构建一个加速器来减轻 CPU 处理常见网络琐事的需要(随意称其为SmartNIC/DPU/IPU ) 并将其绑定到一个分布式服务平台,该平台协调将相关工作负载部署到这些设备中。
“我们正在构建一个处理器,它可以以非常高的速度和低成本进行云处理,”Jain 说,然后断言该公司拥有适合超大规模和小型服务提供商的产品。
该公司两年前从隐身中脱颖而出,其管理团队已经在包括思科在内的其他地方开展了价值数十亿美元的业务,并获得了高通和爱立信的投资。
AMD 对交易的确认表明,Pensando 套件已经在高盛、IBM 云、微软 Azure 和甲骨文云找到了家。
在正式公告中,微软 Azure Girish Bablani 公司副总裁表示:“我们看到基于云的连接相关性能整体提升了 40 倍。Pensando 在不到 12 个月的时间内实现了这一目标。”

甲骨文云执行副总裁 Clay Magouyrk 称赞 Pensando 是“重要的战略合作伙伴”。
同样在收购公告中,AMD 董事长兼首席执行官 Lisa Su 表示:“要建立具有最佳性能、安全性、灵活性和最低总拥有成本的领先数据中心,需要广泛的计算引擎。”
“今天,通过收购 Pensando,我们为我们的高性能 CPU、GPU、FPGA 和自适应 SoC 产品组合添加了一个领先的分布式服务平台……这扩大了我们为我们的云、企业和边缘客户提供领先解决方案的能力。”
对边缘的提及很可能包括运营商和 5G,SmartNIC 有望通过提高基站的计算密度和效率发挥重要作用。
Pensando 首席执行官 Prem Jain 在个人层面和代表 Pensando 都“很高兴加入 AMD 大家庭”,Pensando 将成为 AMD 高级副总裁兼总经理 Forrest Norrod 领导的 AMD 数据中心解决方案集团的一部分。
公告没有解决的一件事是这笔交易对 AMD收购 Xilinx 意味着什么,Xilinx也涉及 SmartNIC。不难看出赛灵思对使用 Pensando 的硅设计感到兴奋。
此次出售预计将在未来 90 天内完成。一旦完成,AMD 可以说比主要竞争对手英特尔拥有更好的 SmartNIC 地位,英特尔仍在整理其硬件,并与 Nvidia 和 VMware 等合作伙伴合作开发编排软件。
后者被认为接近于管理 SmartNIC/IPU/DPU 硬件的商业代码发布,这意味着 AMD 可能在收购 Pensando 时抢了先机。

电子邮件营销公司 MailChimp 周日披露,他们遭到黑客攻击,这些黑客获得了内部客户支持和账户管理工具的访问权限,以窃取受众数据并进行网络钓鱼攻击。
周日早上,Twitter充斥着来自 Trezor 硬件加密货币钱包所有者的报告,他们收到了声称该公司遭受数据泄露的网络钓鱼通知。
这些电子邮件促使 Trezort 客户通过下载允许窃取存储的加密货币的恶意软件来重置他们的硬件钱包 PIN。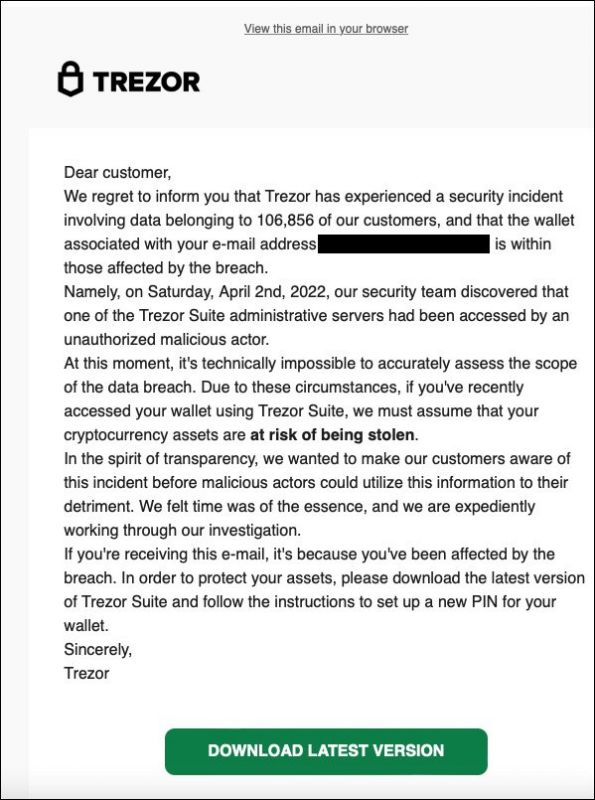
假 Trezor 数据泄露通知
来源: Twitter
Trezor后来分享说,MailChimp 已受到针对加密货币行业的威胁行为者的攻击,他们进行了网络钓鱼攻击。
MailChimp 违规针对加密、金融
在给ZZQIDC的一封电子邮件中,MailChimp 已经证实,这次违规行为比威胁参与者访问 Trezor 的账户更为严重。
根据 MailChimp 的说法,他们的一些员工因社会工程攻击而堕落,导致他们的凭据被盗。
“3 月 26 日,我们的安全团队发现恶意行为者访问了我们面向客户的团队用于客户支持和帐户管理的内部工具之一,”MailChimp 首席信息安全官 Siobhan Smyth 告诉ZZQIDC。
“该事件是由外部参与者传播的,他对 Mailchimp 员工进行了成功的社会工程攻击,导致员工凭证被泄露。”
“我们迅速采取行动,通过终止对受感染员工账户的访问来解决这种情况,并采取措施防止其他员工受到影响。”
这些凭据用于访问 319 个 MailChimp 帐户并从 102 个客户帐户中导出“受众数据”,可能是邮件列表。
除了查看帐户和导出数据外,威胁参与者还获得了对数量不详的客户的 API 密钥的访问权限,这些客户现已被禁用且无法再使用。
应用程序编程接口 (API) 密钥是允许 MailChimp 客户直接从他们自己的网站或平台管理他们的帐户和执行营销活动的访问令牌。
使用这些泄露的 API 密钥,威胁参与者可以创建自定义电子邮件活动,例如网络钓鱼活动,并将它们发送到邮件列表,而无需访问 MailChimp 的客户门户。
Smyth 告诉ZZQIDC,所有受感染的帐户持有人都已收到通知,并且威胁参与者访问了加密货币和金融领域的客户。
MailChimp 表示,他们收到了有关此访问被用于针对被盗联系人进行网络钓鱼活动的报告,但尚未披露有关这些攻击的信息。
MailChimp 建议所有客户在其帐户上启用双重身份验证以进一步保护。
“我们为此事件向我们的用户致以诚挚的歉意,并意识到它给我们的用户及其客户带来了不便并提出了问题。我们为我们的安全文化、基础设施以及客户对我们保护他们数据的信任感到自豪。我们“对我们为保护用户数据和防止未来发生事故而采取的安全措施和强大的流程充满信心。”
Mailchimp 的首席信息安全官 Siobhan Smyth。
这次攻击让人想起 Lapsus$ 黑客组织最近的违规行为,该组织使用社会工程、恶意软件和凭据盗窃来访问众多知名公司,包括Nvidia、三星、微软和Okta。
Okta 的入侵是通过与 MailChimp 类似的方法完成的,即对一个可以访问内部客户支持和帐户管理系统的承包商进行社会工程。
BleepingComputer 已向 MailChimp 和 Trezor 发送了有关违规的进一步问题,但尚未收到回复。
我司采用台湾最大的国际机房(中华电信)保障客戶主机安全,拥有 T3 认证数据中心,支持定制产品服务!
除了中华电信机房外,还有其他优秀机房。
并提供不同的带宽:默认10M,
不限制网速流量,享有最顺畅的网路品质!
机房拥有24小时值班人员,提供免費重開机服務。
最短交付时间2-5小时,最慢12小时
可根据用户的需求安装系统
60.250.76.49

详情点击:台湾服务器
订购前请阅读一下规则:
所有主机不支持VPN 协议(包含但不限于:科学上网上、外貿、翻墙、飞机、机场、梯子、551、SSR、V2ray、FQ、Trojan)。
因实体主机,已经开通不提供退款。
从2021年6月不再提供免费测试服务,如需要测试,请支付资源占用测试费用100元押金费用(可测试3小时,满意可续订,减去100元押金,测试后不续订,100元不返还)
Windows系统请使用2G内存或2G以上内存机型,若只使用1G导致内存不足,本公司不负责相关责任。
禁止:暴力、賭博、诈骗、侵权、攻击、政治信息,仿牌、假冒医药、代理伺服器(VPN)、等一切国家法律禁止之內容,一经发现,立即关闭主机,不予退款,并上报相关机关处理。
主机IP接由系統随机分配IP不指定IP,如果IP被封,急需IP,请支付一定服务费用进行获取IP

一种名为 Borat 的新型远程访问木马 (RAT) 已出现在暗网市场上,提供易于使用的功能来进行 DDoS 攻击、UAC 绕过和勒索软件部署。
作为 RAT,Borat 使远程威胁参与者能够完全控制受害者的鼠标和键盘,访问文件、网络点,并隐藏他们存在的任何迹象。
该恶意软件允许其操作员选择他们的编译选项来创建小型有效负载,这些有效负载正是他们需要进行高度定制的攻击。
Cyble的研究人员对 Borat 进行了分析,他们在野外发现了它,并对恶意软件进行了采样,以进行一项揭示其功能的技术研究。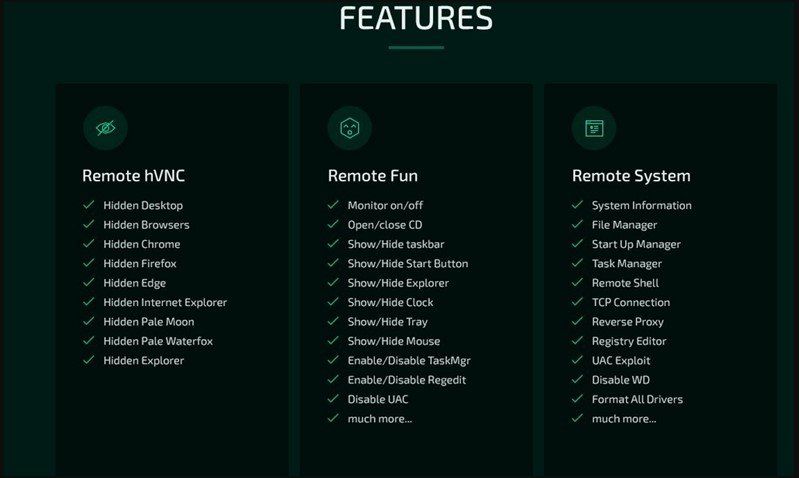
Borat 的一些功能 (Cyble)
广泛的功能
目前尚不清楚 Borat RAT 是否在网络犯罪分子之间出售或免费共享,但 Cycle 表示它以包含构建器、恶意软件模块和服务器证书的包的形式出现。
Borat RAT 档案 (Cyble)中的文件
该木马的功能,每个都有自己的专用模块,包括以下内容:
键盘记录 - 监控和记录按键并将它们存储在 txt 文件中
勒索软件——将勒索软件有效载荷部署到受害者的机器上,并通过 Borat 自动生成勒索记录
DDoS – 使用受感染机器的资源将垃圾流量引导到目标服务器
录音- 通过麦克风录制音频(如果有),并将其存储在 wav 文件中
网络摄像头录制- 从网络摄像头录制视频(如果有)
远程桌面- 启动隐藏的远程桌面以执行文件操作、使用输入设备、执行代码、启动应用程序等。
反向代理——设置反向代理以保护远程操作员的身份不被暴露
设备信息——收集基本系统信息
进程空心化——将恶意软件代码注入合法进程以逃避检测
凭据窃取– 窃取存储在基于 Chromium 的 Web 浏览器中的帐户凭据
Discord 令牌窃取– 从受害者那里窃取 Discord 令牌
其他功能——通过播放音频、交换鼠标按钮、隐藏桌面、隐藏任务栏、按住鼠标、关闭显示器、显示空白屏幕或挂起系统来扰乱和迷惑受害者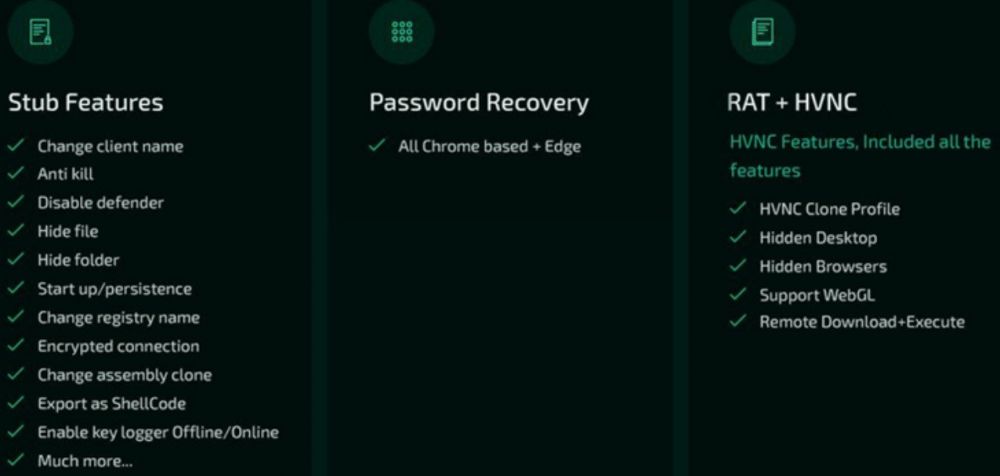
更多 Borat 的广告功能 (Cyble)
正如 Cyble 的分析所指出的,上述功能使 Borat 本质上是一种 RAT、间谍软件和勒索软件,因此它是一种强大的威胁,可以在设备上进行各种恶意活动。
总而言之,尽管 RAT 的开发人员决定以喜剧电影 Borat 的主角(由 Sacha Baron Cohen 化身)的名字命名,但该恶意软件根本不是开玩笑的。
通过深入挖掘试图找到该恶意软件的来源,Bleeping Computer 发现该有效载荷可执行文件最近被识别为 AsyncRAT,因此它的作者很可能基于他的工作。
通常,威胁参与者通过伪装成游戏和应用程序破解的附加可执行文件或文件分发这些工具,因此请注意不要从不可靠的来源(如种子或阴暗网站)下载任何内容。

一个受损的 Trezor 硬件钱包邮件列表被用来发送虚假的数据泄露通知,以窃取加密货币钱包和存储在其中的资产。
Trezor 是一个硬件加密货币钱包,它允许您离线存储您的加密资产,而不是使用基于云的钱包或存储在您 PC 上的更容易被盗的钱包。
设置新的 Trezor 时,将显示一个 12 到 24 字的恢复种子,如果他们的设备被盗或丢失,所有者可以恢复他们的钱包。
但是,任何知道此恢复种子的人都可以访问钱包及其存储的加密货币,因此将恢复种子存储在安全的地方至关重要。
从今天开始,Trezor 硬件钱包所有者开始收到数据泄露通知,提示接收者下载伪造的 Trezor Suite 软件,该软件会窃取他们的恢复种子。
Trezor 在 Twitter 上证实 ,这些电子邮件是通过他们在 MailChimp 托管的选择加入时事通讯发送的网络钓鱼攻击。
Trezor 后来表示,据称 MailChimp 证实他们的服务受到了针对加密货币公司的“内部人员”的破坏。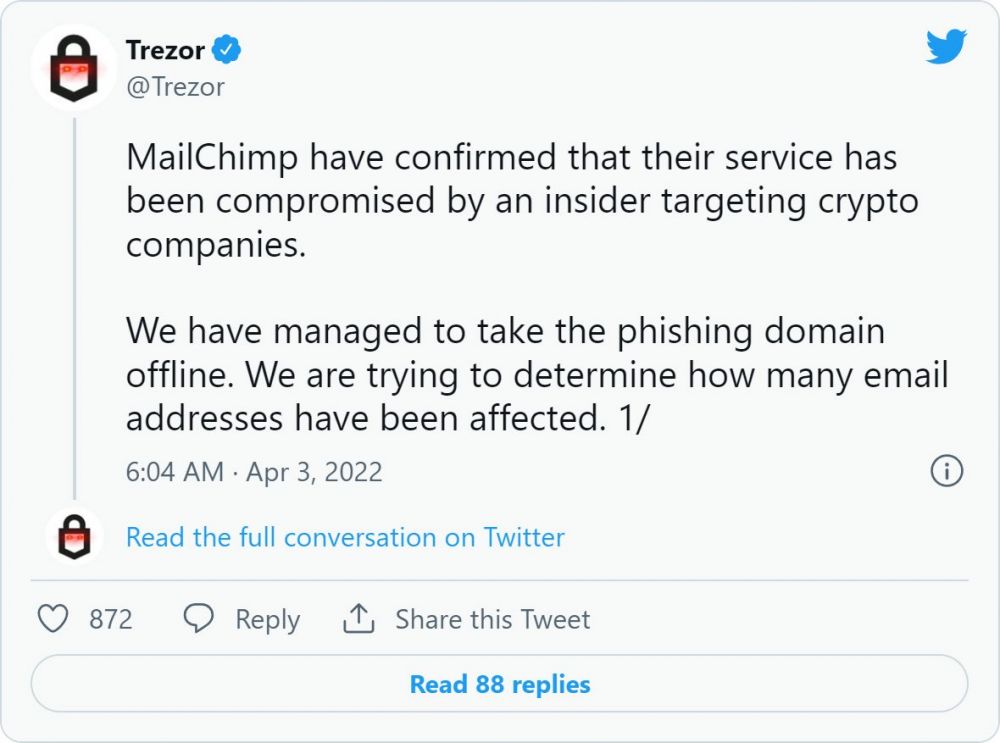
ZZQIDC已联系 MailChimp 以了解有关此妥协的更多信息,但目前尚未收到回复。
深入了解 Trezor 攻击
网络钓鱼攻击始于 Trezor 硬件钱包所有者收到声称是数据泄露通知的虚假安全事件电子邮件。
“我们很遗憾地通知您,Trezor 经历了涉及属于我们 106,856 名客户的数据的安全事件,并且与您的电子邮件地址相关联的钱包 [email here] 属于受违规影响的人。”假 Trezor 写道数据泄露网络钓鱼电子邮件。
这些虚假的数据泄露电子邮件称,该公司不知道泄露的程度,所有者应下载最新的 Trezor Suite 以在其硬件钱包上设置新的 PIN。
该电子邮件包含一个“下载最新版本”按钮,该按钮将收件人带到一个网络钓鱼站点,该站点在浏览器中显示为 suite.trezor.com。
然而,该网站是一个 使用 Punycode 字符的域名 ,允许攻击者使用重音或西里尔字符冒充 trezor.com 域,实际域名为 suite.xn--trzor-o51b[.]com。
需要注意的是,合法的 Trezor 网站是 trezor.io。
这个假网站会提示用户下载 Trezor Suite 应用程序,如下图所示。
钓鱼网站推假 Trezor Suite
来源:zzqidc
除了 suite.xn--trzor-o51b[.]com 网站,攻击者还在 URL 上创建了网络钓鱼站点:当访问者下载桌面应用程序时,它将从名为“Trezor-Suite-22.4.0-win-x64.exe”的网络钓鱼站点下载一个虚假的 Trezor Suite 应用程序。
正如您在下面看到的,合法的 Trezor Suite 应用程序是使用“Satoshi Labs, sro”的证书签名的,而伪造的 Windows 版本 [ VirusTotal ] 是由“Neodym Oy”(右)的证书签名的。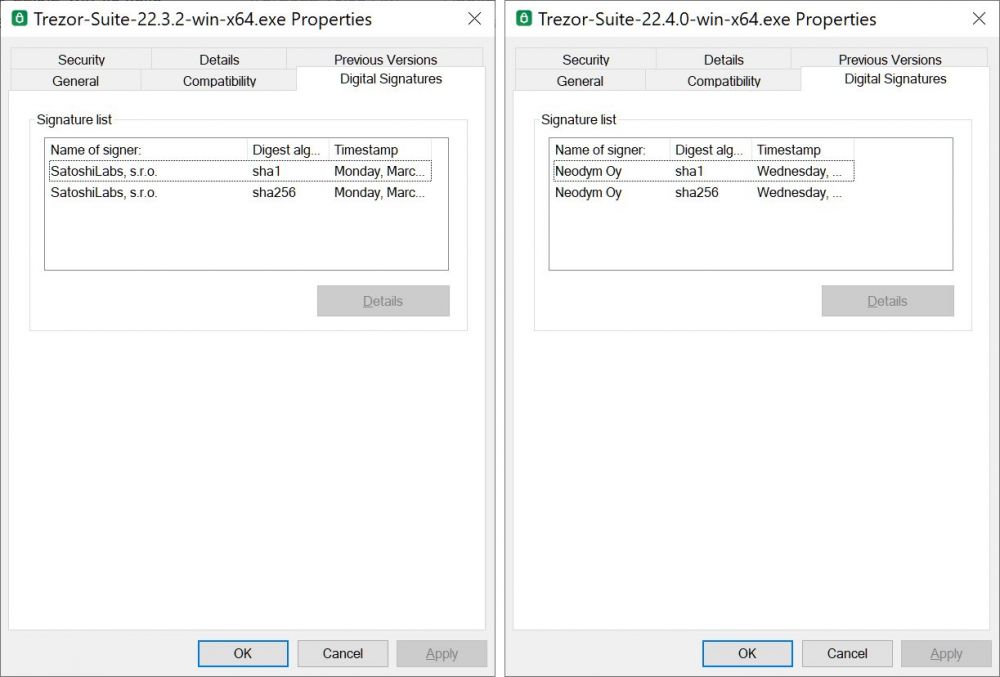
伪造和合法 Trezor Suite 下载的数字签名比较
来源:ZZQIDC
由于 Trezor 套件是开源的,攻击者下载了源代码并创建了自己的修改后的应用程序,该应用程序看起来与原始的合法应用程序相同。
具有讽刺意味的是,这个伪造的套件甚至在应用程序的屏幕顶部包含了 Trezor 关于网络钓鱼攻击的警告横幅。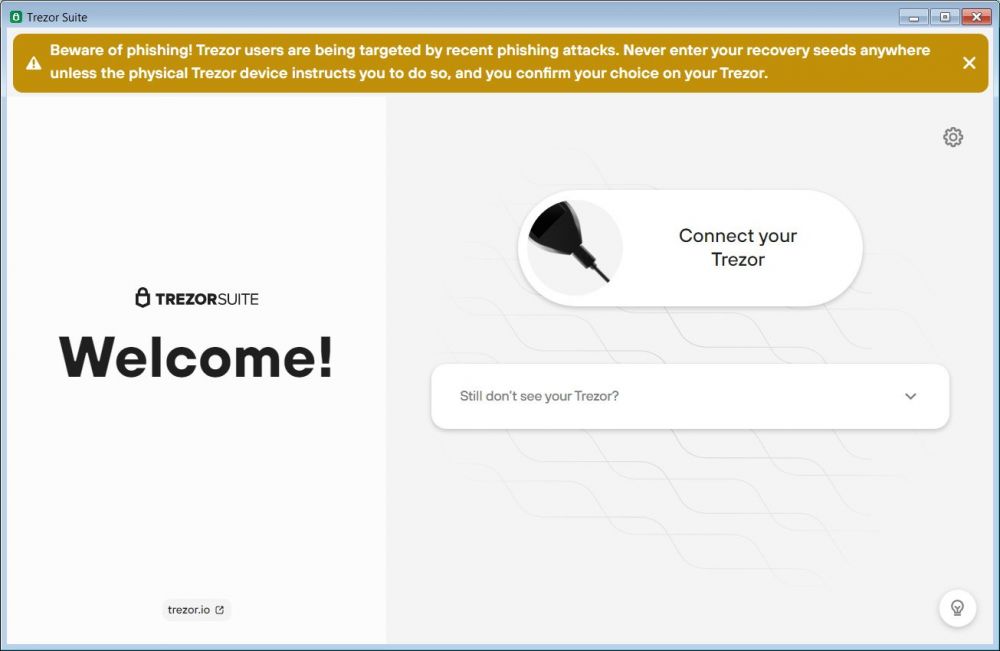
假 Trezor Suite 软件
来源:ZZQIDC
然而,一旦 Trezor 所有者将他们的设备连接到伪造的 Trezor Suite 应用程序,它就会提示他们输入 12 到 24 个单词的恢复短语,该短语会被发送回威胁参与者。
既然威胁参与者有了你的恢复短语,他们就可以使用它将恢复短语导入他们自己的钱包并窃取受害者的加密货币资产。
针对 Ledger 硬件加密钱包所有者的几乎相同的攻击希望网络钓鱼攻击导致伪造的 Ledger Live 软件。
Trezor 所有者应该怎么做?
首先,切勿在任何应用程序或网站中输入您的恢复种子。只能在您尝试恢复的 Trezor 设备上直接输入种子。
由于创建冒充合法网站的相似域很容易,因此在涉及加密货币和金融资产时,请始终在浏览器中键入您尝试访问的域,而不是依赖电子邮件中的链接。
这样,您就知道您要去的是合法站点,而不是冒充它的站点。
此外,Trezor 的官方网站位于 trezor.io,因此其他域,例如 trezor.com,与加密硬件钱包公司无关。
最后,忽略任何声称来自 Trezor 的电子邮件,说明您受到最近数据泄露的影响。如果您担心,请直接联系 Trezor 以获取更多信息,而不是单击这些电子邮件中的链接。

还记得在任何给定的服务器 CPU 中只有几种处理器可供服务器使用吗?可能有几十家供应商,但他们并没有给太多选择,今天,我们只有少数服务器 CPU 设计人员和几家代工厂来进行蚀刻,但计算引擎的种类繁多。
鉴于摩尔定律在晶体管价格/性能方面的改进放缓以及现代服务器需要支持的工作负载的扩大,这是绝对必要的。在 AMD,需要在客户定制需求和企业需要拥有一条有意义且有利可图的产品线之间取得平衡的人是 Dan McNamara,他是服务器业务的高级副总裁兼总经理。
McNamara 的整个职业生涯都在半导体行业,包括在 2004 年加入 FPGA 制造商 Altera 担任业务发展总监之前,创立了一家公司并在另一家公司做销售。在 Altera,McNamara 曾担任销售总监,然后负责应用工程,然后负责 FPGA 制造商的嵌入式部门。当英特尔在 2015 年以 167 亿美元收购 Altera 并创建可编程解决方案集团时,McNamara 经营了四年,然后被任命为网络和自定义逻辑集团的总经理。2020 年 1 月,McNamara 加入 AMD 以帮助引导公司向数据中心扩张——虽然我们没有谈论这个,但可能对 X86 服务器芯片供应商购买 FPGA 制造商有很多想法。
对于这次谈话,我们想坚持现在和未来五到十年内服务器芯片和架构正在发生的事情。
Timothy Prickett Morgan:让我们从上周宣布的“Milan-X”Epyc 服务器芯片及其 3D V-Cache 开始。我们如何看待这种风格的 Epyc 服务器芯片的流行,什么时候所有芯片都有 3D V-Cache?我意识到在制造难度和性能提升之间存在权衡,但如果你试图最大化芯片复合体上的核心空间,那么垂直使用 L3 缓存可能是一个不错的策略,即使对于相对而言小筹码。
Dan McNamara:这是一个有趣的问题,3D V-Cache 是我们更大愿景的一部分,即计算将走向何方,对吧?Milan-X 是通往不同优化点的漫长路线图中的一个点。使用“Naples”Epyc 7001s,我们的客户和我们对通用计算有一个独特的看法,而使用“Rome”Epyc 7002s,我们做了常规版本和高频版本。有了“Milan”Epyc 7003,我们有 Milan、Milan 高频,现在还有带有堆叠缓存的 Milan-X。
去年 11 月,我们对此进行了很多讨论,在这个更广泛的计算大周期中,我们真的相信这是未来,我们相信客户正在寻找许多优化点。
因此,当您从 TCO 和性能的角度来看待 Milan-X 时,想想一个客户试图针对电子设计自动化、计算流体动力学、流体动力学等进行优化。但我们也相信,这就是未来的开始。我们还没有透露很多 Epyc 路线图,但我们在客户端和服务器上都有 3D V-Cache,客户将进行优化,并在它提供真正价值时这样做。
TPM:我明白了。但是,当我看到一个处理复合体时,我知道 3D 堆叠将成为一个问题,因为计算核心会产生热量,而且我知道我可以将 L3 缓存加倍堆叠并获得三倍容量,因为 V-Cache 搭载片上缓存的 I/O 密度是片上缓存的两倍,因此我可以很容易地取回更多的套接字区域来添加内核或加速器或其他任何东西,我想我会这样做一旦制造完善并且可能更实惠,这是理所当然的事情。仅通过堆叠 L3 高速缓存,您就可以在裸片上获得 20% 到 30% 的核心。我认为将出现一个转折点,因为这个原因,这项技术无处不在。对于那些对缓存非常敏感的技术工作负载,您可能会增加三倍堆栈 L3 以进一步提升它。. . .
Dan McNamara:理论上,你是完全正确的,让我稍微扩展一下。如果你考虑未来五年左右的时间,它不仅仅是堆叠内存,而且你知道,在 CPU 内核上。套接字完全异构。因此,能够在封装或板上提供更多异构组件的公司将在这个新时代获胜。
另一件事,我认为你打到了头,是你在 CPU 复合体中的基本级别是什么,然后从那里适当地堆叠。我们与台积电建立了合作伙伴关系,这是一种我们共同开发的混合键合技术,没有微凸点。而且我们知道我们不能将这种表现留在桌面上,我们不能等待,我们现在必须做点什么。但我们也没有试图在这里沸腾海洋,我们知道,我们的 OEM 和 ODM 合作伙伴都知道 Milan-X 并不适合一切。如果你想要好的 TCO、高密度的 VM,那么普通的 Milan 是很好的选择。
正如您从我们的路线图中了解的那样,我们将分叉并更加关注未来。“热那亚”拥有 96 个内核和一个阶跃函数,为核心企业、公共云和高性能计算带来大量额外计算。有了“Bergamo”,我们带来了完全不同的视角,拥有 128 个核心并针对云原生工作负载进行了优化,具有低功耗和非常好的能效和更高的密度。
TPM: 我认为这是一个大容量通用计算时代,你可以通过轻微的 SKU 变化将一千万件产品推向市场,这更多是为了最大限度地提高芯片产量并从功能中获取更多利润。结束了。但是,小批量、精确调整硬件的时代才刚刚开始,您可能只能制作几十万到一百万个特定设计。在任何给定时间,公司的机队中可能只有三个、四个或五个或六个不同的服务器 SKU,但服务器设计的变化,从套接字内部到节点中的套接字和外围设备,将在世界排名前几千的组织中相当高。
丹·麦克纳马拉:你明白了。
TPM:让我们换个档次。服务器市场与十年前的市场对比如何,五年甚至十年后又会是怎样?
Dan McNamara:我认为这正是我们在这里谈论的内容。未来真的是关于不同的优化点,将正确的优化点和软件结合起来,实现异构计算。如果你看看今天的高端超级计算机,它完全是异构的,有 CPU 和 GPU 以及各种不同的技术。随着我们的前进,CPU之外会有不同的优化点。我们有 SmartNIC 和 GPU,以及对等连接。优化正在从仅使用 CPU 完成到使用整个系统完成。
TPM:在我看到的未来,什么是服务器的定义将会变得模糊,即使什么是分布式计算系统的定义也不会更加模糊。这些组件的组织和编排方式与我们今天的方式不同。
我不知道那一天是什么时候,但我认为我所知道的服务器——安装在机架中的 1U、2U 或 4U 外形尺寸的金属外壳的盒子——正在消失。我认为新的计算单元可以扩展 PCI-Express 和 CXL 以及其他覆盖。也许这个计算单元是几个机架,或者整排,或者可能是几排吊起来的。我不知道。但在此范围内,将有 CPU、GPU、FPGA 和定制 ASIC 托盘,它们有少量自己的内存和共享 DDR 内存托盘、共享持久内存托盘,以及构成存储层次结构的机架中的共享闪存存储托盘以及不同层次和层次的互连将这一切结合在一起并将其连接到外部世界。这是新主板。有趣的是,在计算引擎插槽内,
Dan McNamara:我认为这是正确的。你知道,分类计算已经讨论了很长时间,但是未来会有不同内存的孤岛或不同形式的计算孤岛。确实。你今天在云中看到了它,对吧?
TPM: 嗯,我们仍然有服务器,并且机器内部仍然有一个服务器主板,无论它是否有皮肤。但是我们将需要小板或类似的东西来将所有这些静态硬件配置分解成更小的、可组合的系统,然后拥有非常复杂的工作负载管理工具来保持所有这些东西以高利用率运行。这个旋转复合体中不应该有没有被使用的组件。让它在后台进行基于云的蛋白质折叠。. . .
我担心的是,所有这些组装起来的组件之间的 I/O 会吃掉我们的生命,但我想不出更好的方法来做到这一点。
Dan McNamara:确实担心 I/O。对于 I/O,您需要考虑的另一件事是卸载。看看今天的系统,尤其是在云中:您的机器上有存储空间,而您正在浪费存储周期。你为什么要这样做?获取 SmartNIC 并加速它。我们将看到越来越多的这种情况,人们不会将宝贵的周期浪费在可以卸载的东西上。问题是我们如何简化 I/O 以使延迟和带宽处于最佳状态?
TPM: 我在数据中心的任何地方都看到了大规模定制。
Dan McNamara:每个人都在关注大量数据,并试图弄清楚我们如何创造更多的智能和更好的结果。所有这些都需要计算,并且趋势是越来越多的计算。而且我认为我们都在谈论的这种优化肯定会发生,并且会在未来发生更多。AMD 刚刚开始发生这种情况,我们看到了 Milan-X 的一个很好的例子。我们相信这将是一场巨大的胜利,我们知道这并不适合一切。
TPM: 我不认为在第一个版本中,3D V-Cache 可能占 SKU 销售量的 10% 或 20%,但也不会达到 50%。
Dan McNamara:我们不会在那个细节级别上谈论事情,但是不,不会是 50%。我们必须培训我们的销售团队并确保他们了解 3D V-Cache 并不适用于所有工作负载。他们现在知道米兰和米兰-X分别针对的是什么。
TPM: 关于 AMD 在服务器市场份额增长的道路上你能说些什么?我一直在寻找超过 25% 服务器份额阈值的那一天。
丹·麦克纳马拉:我不能说太多。但是您知道,我们显然对我们的份额抱有很高的期望,并且您已经关注了 2021 年和 2022 年初的财务状况。再说一次,我们刚刚进入了一个安静的时期。. . .
TPM: [笑声]你当然做到了!很好的安排这次面试。
最后一个问题:您是否考虑过在您的大规模优化未来可能需要做四路和八路服务器?
Dan McNamara:我们没有公开记录四插槽或更大机器的计划。但我们总是关注它,随着我们发展生态系统,这是一件有趣的事情。我们确实遇到了需要更大内存占用的客户,而 SAP HANA 绝对是更大内存占用和 2P 规模以上规模的关键所在。但是我们现在没有任何公开的计划。
TPM: 嗯,数量不多,但有一些利润。我们怀疑,在每个 SKU 世界的较低数量中,CPU、GPU 和 FPGA 的大规模定制 SKU 也会出现这种情况。如果 TCO 对客户来说效果更好,即使使用成本更高的芯片,您也能够以更高的 ASP 以更低的数量弥补它。这不是很好笑吗?

随着 HPC 和 AI 工作负载变得越来越大,并且对计算能力和带宽能力的要求越来越高,系统架构师在思考未来系统时正试图找出养活这头野兽的最佳方式。
一种系统设计方案涉及将尽可能多的东西塞到硅片上,在封装内集成尽可能多的东西,快速互连可在组件之间提供更低的延迟。这可以从将 CPU 和 GPU 加速器放在混合芯片上的努力中看出,例如 AMD 的加速处理单元 (APU)、Nvidia 的“Grace” CPU 和“Hopper” GPU 混合,以及英特尔即将推出的“猎鹰海岸”套餐。
另一种系统设计方法是分解组件,创建一个可组合的基础架构环境,其中计算和网络被分解为更小的部分,这些部分基本上可以组合成一个资源池,可以根据工作负载的需要进行利用。所需的 CPU 和 GPU 功率以及应用程序使用的内存、I/O 和其他组件从池中获取,然后在工作完成后返回到池中以供其他工作负载使用。
去年我们写过这篇文章,当时可组合织物制造商 Liqid 被国家科学基金会选中,在德克萨斯 A&M 大学安装的名为 Accelerated Computing for Emerging Sciences (ACES) 的原型系统中使用其 Matrix 织物和 Liqid 指挥中心控制器。
这也是德克萨斯高级计算中心 (TACC) 的工程师正在使用其Lonestar6 超级计算机在一个新项目中进行测试的方向,TACC 正在与 GigaIO 在测试平台上合作,以了解这种可组合环境如何工作。
我们猜想,德克萨斯州有一些关于可组合超级计算的东西。
“这是我们在可组合性方面的实验之一,”TACC 执行董事 Dan Stanzione 告诉The Next Platform。“目前这在某种程度上是一个研究项目,但我们正在将其连接到生产系统中,我们将使其可供用户使用并衡量效率。我们将有一些节点直接连接 GPU,然后有一些节点通过这个 PCI 交换机基础设施连接 GPU。我们可能还会在其中添加一些 NVM-Express 设备,但目前,我们只是放入 GPU 以开始使用。”
Lonestar6 是位于德克萨斯州奥斯汀的超级计算机中心的最新集群,这是一个 600 个节点的系统,包括由AMD 的 Epyc“米兰”服务器芯片和Nvidia 的“Ampere”A100 GPU驱动的戴尔系统,并通过 Mellanox 的 HDR InfiniBand(Nvidia 2019 年以 70 亿美元收购)。每个计算节点运行两个 64 核 Epyc 7763 芯片和 256 GB 的 DDR4 内存,而 GPU 节点拥有两个 Epyc 芯片和两个 GPU,每个都有 40 GB 的高带宽内存。鉴于 Lonestar6 运行的数千个工作负载中的很多都没有被重构为由 GPU 加速,因此 Lonestar6 机器中的纯 CPU 节点比配备 GPU 的节点要多得多。
TACC 的 Lonestar6 超级计算机
该机器于今年早些时候投入全面生产,不仅被德克萨斯大学奥斯汀分校的研究人员和学者使用,还被德克萨斯 A&M、德克萨斯理工大学和北德克萨斯大学的研究人员和学者使用,这是一个通用系统Stanzione 说,谁需要同时使用 CPU 和 GPU。
对于该项目,GigaIO 正在利用其可组合基础设施功能来创建分散式服务器基础设施,利用 PCIe 和供应商的通用可组合结构,称为 FabreX。该架构(包括架构管理器、架顶式交换机和网络适配器卡)可根据工作负载的需求快速配置资源,从而创建包含加速器、存储和内存的集群架构。目标是使计算和存储等系统组件更易于访问和共享,从而降低运营和资本成本。
TACC 正在将 GigaIO 技术放入 Lonestar6 的一片片中,大约有 16 个插槽,工程师可以在其中放置 GPU 或 NVM-Express 设备。现在他们将使用 A100 GPU,包括四个 GPU 的静态节点和其他用户可以请求通过结构组成的一个、两个、四个或八个 GPU。
Stanzione 说,GPU 的成本是该项目背后的驱动力。
“GPU 的成本远高于处理器,”他说。“在构建这些多加速器节点时,它们在某种程度上是节点中的主要成本。这是配备 Grace 处理器的 Nvidia 将接管生态系统的原因之一。在他们看来,在某种程度上,它是围绕 GPU 的外壳和数据移动系统。”
不是每个人都能负担得起扩展至他们可能想要的程度,因此 GigaIO 的结构和技术(例如用于 HPC 环境的高速 I/O CXL 标准)是未来发展的先驱。
“现在——尤其是 CXL——是关于,我们能否摆脱这个单一和静态计算节点的概念,转而支持这个可组合的世界,在这个世界中,我们有处理元素、存储元素、存储元素,也许还有加速处理元素,我们可以将每个工作负载组合到最佳屏幕中,”Stanzione 说。“所有这些事情都存在差异,但我们知道我们有很多应用程序,每个节点的速度大约为 2 GB/秒。如果您购买四个 GPU 节点,然后将这些工作放在那里,那么您将经常浪费一半的节点。我们还有其他的,特别是在单节点模型——并行 AI 中——它们可以扩展到尽可能多的用户,并共享每个节点四个、八个、十六个等命名空间。但与其他一切相比,这些都相当少而且相差甚远。”
一种选择是购买混合节点——这发生在一些大学规模的集群中——并且系统被分成小的异构口袋,从而优化了每个工作负载的系统。如果有很多工作需要 GPU,而不是让一些加速器闲置,可以将它们分配给另一个节点,从而更好地利用资源。然而,这在很大程度上依赖于成本和性能之间的权衡。
“就像所有事情一样,关键在于延迟,这在我们的早期测试中看起来相当不错,因为您实际上是在开箱即用它,即使它仍然是 PCIExpress,”他说。“我们增加了一点延迟。它运行得那么顺利吗?您是否需要 NVLink 或CXL 中的连贯性等功能才能真正获得最佳性能,仍然存在广泛的争论。有很多应用程序的 PCI-Express 就足够了,尤其是现在我们有 PCI-Express 4.0 和即将推出的 PCI-Express 5.0。对于许多可以让我们从 GPU 中获得足够好处的代码。在这些情况下,花钱购买 NVLink 之类的东西并不能真正提高性能。”
根据 Stanzione 的说法,这在很大程度上将取决于 AI 软件堆栈的发展方式。然后该行业将了解应该进行哪些权衡。但是,有许多应用程序可以通过同一硬件提供大型多 GPU 节点或多个 GPU 节点的必要性能,因此站点不必购买更多硬件,然后有时让它闲置。
并且利用很重要。TACC 发现其集群中 GPU 和 CPU 的利用率百分比在 80% 到 90% 之间。也就是说,有不同的方法来确定利用率,他说。一个是确定节点是否分配给正在运行作业的用户。另一个是用户使用分配给他们的节点的效率。
更可组合的环境是解决一些利用率问题的一种方式。一些工作需要 GPU 之间的紧密耦合才能扩展,但其他工作(如 AMBER 或 NAMD 分子动力学工作负载)更小,不需要太多带宽即可通过添加 GPU 来获得良好的性能。在去中心化的环境中,调度程序更容易更有效地将 GPU 分布在各种工作负载上,并且必须考虑结构的成本。
“我们正在为结构增加一些成本,这是我们必须理解的权衡之一,因为基本上我们提供给 Giga IO 的所有美元都存在节点成本的增量 [即] 不用于 GPU 和CPU,”Stanzione 说。“这可能是一个很大的部分,但我们必须弄清楚我们增加多少效率与我减去多少美元来花在硬件上的模型。坦率地说,我们可以运行并且我们将对此进行一些实验室基准研究,可能会发表关于这类事情的论文。但要理解这种权衡,我需要在野外使用真实的用户代码运行它。”
这一切是如何摆脱的——趋势是将所有东西集中在硅封装上还是运行可组合的基础设施——尚不清楚。
“我们每年仍然有更多的晶体管空间,”他说。“这就是我们仍然做对的事情是每个芯片更多的晶体管。如果我们开始关注芯片或封装上耦合的 CPU [和] GPU 会怎样?这是否可能 [提供] 数量级的对 CPU 的虚函数调用的改进?也许未来会是,我们现在将计算节点中的所有内容都放在一个单独的包中,然后您只需将这些包存在于某个结构中,这将朝着另一个方向发展,在硅片上集成更多。问题是——就像所有事情一样——我们希望耦合到什么程度?自从集群与向量机出现以来,我们基本上就一直在争论这个问题。传统智慧也经常被证明是错误的。”
这就是为什么像 TACC 这样的地方做实验,所以把一些事实和数据带到一个不确定的未来。
“过去的教训是,我们并不真正知道答案,即使我们认为我们知道,”Stanzione 说。“我们最终可能会进入一个完全分散的世界,在那里我们制造一些廉价的小部件。吸引我的一个原因是所有东西都在模具上,我们在这些东西中获得了荒谬的力量,最终它们很难冷却。你没有足够的表面积,即使我们在上面运行液氮,我们也没有足够的表面积来提取热量。然而,如果我只用几个内核构建非常小的芯片,我们可以将它们组合在一个结构上……我们可以将时钟频率提高到我们都希望它达到 10 GHz 或类似的频率,然后将它们加速到 200-瓦特处理器具有更少的内核,然后我们将所有这些聚合到一个结构中。这可能是一个完全不同的世界。
当Nvidia 在 2019 年 3 月宣布以 69 亿美元收购 Mellanox Technologies 时,每个人都花了很多时间思考两家公司之间的协同效应,以及网络将如何成为运行 HPC 和 AI 的分布式系统中越来越重要的一部分工作量。据我们所知,并非所有人都认为 Nvidia 创建的用于将其 GPU 相互连接并扩展其系统的模拟信号电路是该交易的战略部分。
但是,事实证明,他们是。更具体地说,Nvidia 在设计串行器/解串器电路方面的专业知识 - 芯片的一部分,它采用并行数据流并将其转换为适合通过网络发送的串行数据流 - 在新的 Spectrum-4 800 中发挥了重要作用Nvidia(前身为 Mellanox)最近在 GTC 会议上宣布的 GB/sec 以太网交换机。
早在 2016 年,当我们看到用于数据中心的“Pascal”GP100 GPU 上的 20 Gb/秒 NVLink 端口时,我们就知道 Nvidia 在 SerDes 方面非常出色,而且我们真的看到该公司在泄露 NVSwitch 内存时对 SerDes 是认真的基于“Volta”GV100 和“Ampere”GA100 GPU 的 DGX 系列系统的核心区域网络交换机,以及用于 GPU 的独立式多层 NVLink 4.0 内存互连,将在未来 DGX H100 中使用基于“Hopper”GH100 GPU 的系统是极高带宽和低延迟的开关,我们在此处详细讨论过,其电路可与 Mellanox、Broadcom、Marvell 和其他公司所能承受的任何产品相媲美。
事实上,Nvidia 开发的 SerDes 专业知识对 Mellanox 团队非常有价值,这也是为什么使用 Spectrum-4 交换机,该公司正在从 Spectrum-12.8 Tb/秒的总带宽跃升的原因之一- 3 ASIC 于 2020 年 3 月直接发布了 25.6 Tb/秒的设备,许多人一直期待 51.2 Tb/秒的 Spectrum-4 ASIC。
“在数字方面,借助数据包处理引擎,我想说的是,Mellanox 在市场上遥遥领先,”Nvidia 以太网交换机和 DPU 营销副总裁 Kevin Deierling 表示。“我认为我们拥有世界上最好的数字交换机。现在,作为 Nvidia 的一部分,我们正在利用来自 Nvidia 的世界上最好的模拟 SerDes。模拟电路通常是到达芯片的最重要的项目,您必须确保它能够正常工作。数据包引擎,骰子的数字部分,如果你模拟了它,那就是它的行为方式,就是这样。对于模拟,它既是一门艺术,也是一门科学。”
Deierling 还没有准备好详细说明在 Spectrum-4 ASIC 中使用了 Nvidia 的哪些 SerDes,但他确实告诉我们,SerDes 的性能和功率以及光收发器的节省将成为Spectrum-4 的故事,Nvidia 将在今年晚些时候向我们透露,在 ASIC 及其同伴 ConnectX-7 SmartNIC 和 BlueField-3 DPU 全部批量发货之前进行更深入的研究。我们强烈怀疑 S[pectrum-4 中的相同 SerDes 用于 NVSwitch 3 和 NVLink Switch 1 芯片,但我们还不能证明这一点。
我们可以告诉你的是,Spectrum-4 ASIC 实际上是集成的小芯片的集合,Deierling 不敢说。据我们所知,数字封装和环绕它的通信 SerDes 都是在同一个 4 纳米 4N 工艺中实现的,该工艺来自代工合作伙伴台积电,也用于蚀刻新的“Hopper”GH100显卡。有趣的是,Hopper GPU 是具有 800 亿个晶体管的单片芯片,而 Spectrum-4 ASIC 具有小芯片架构,并且在整个复合体中具有 1000 亿个晶体管。
在未来,可以合理地预期数据包引擎将缩小到更小的晶体管几何尺寸,但考虑到使 SerDes 更小并不总是产生更好的性能,未来几代的 Spectrum ASIC 复合体的 SerDes 块将保持在4N过程。AMD 在其 Epyc 处理器复合体中的 I/O 集线器上也做了同样的事情。对于“Milan”Epyc 7003,I/O 集线器采用 GlobalFoundries 12 纳米工艺蚀刻,但与之相连的计算核心芯片采用台积电 7 纳米工艺蚀刻。
Spectrum-4 ASIC 核心的数据包引擎每秒可处理 376 亿个数据包,是Spectrum-2 每秒可处理 95.2 亿个数据包的 4 倍,而我们估计 Spectrum-每秒可处理约 190 亿个数据包。 3或大约 2 倍的吞吐量。数据包处理速率并不总是与交换机系列的带宽增长同步增长,Mellanox 一直试图在这一指标上击败竞争对手。Spectrum-3 芯片是采用 TSMC 16 纳米工艺蚀刻的单片芯片。
与之前的 Spectrum ASIC 一样,Spectrum-4 ASIC 复合体上的 SerDes 可以组合成 2、4 或 8 个组,以创建给定带宽的以太网端口——在本例中为 200 Gb/秒、400 Gb/秒、和 800 Gb/秒,因为通道速度为 100 Gb/秒(即在去除编码开销之后)。原生信号传输速率为 50 Gb/秒,并且采用 PAM-4 脉冲幅度调制编码,允许每个信号通过两个比特,有效通道速度达到 100 Gb/秒。因此,凭借 2、4 或 8 个通道,Spectrum 4 芯片可以以 200 Gb/秒的速度驱动 256 个端口,以 400 Gb/秒的速度驱动 128 个端口,以 800 Gb/秒的速度驱动 64 个端口——后者对于内部的数据中心互连很重要可以通过以太网线跨越的区域。
对于那些数据中心互连(或所谓的 DCI)用例来说,同样重要的是 Spectrum-4 ASIC 内置了 MACsec 加密,这意味着传输中的数据可以以四分之一的线路速率(或者可能更精确,在以 800 Gb/秒运行的端口的四分之一或以 200 Gb/秒运行的所有端口上)。超大规模和云构建者中用于 DCI 应用程序的交换机的平均加密速率约为 4 Tb/秒,因此是该速率的 3 倍多。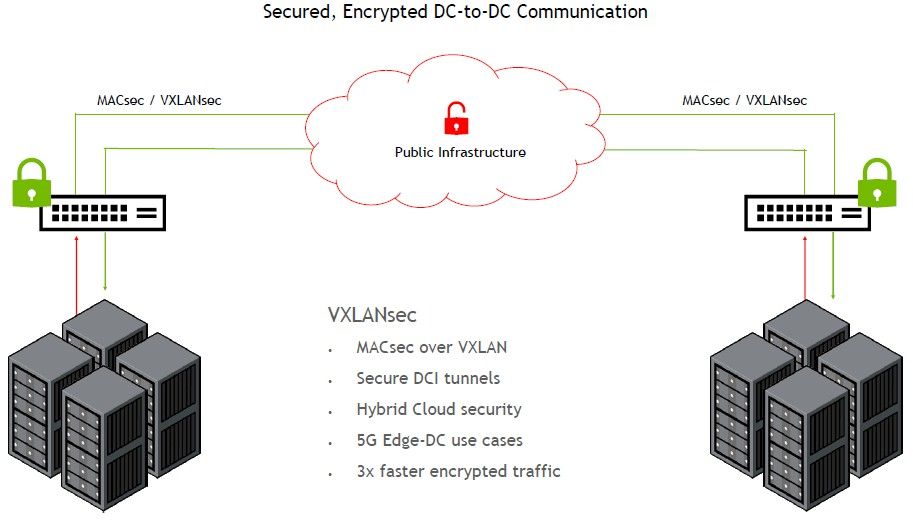
看到 Nvidia 可以将 Spectrum-4 ASIC 分解为以 100 Gb/秒的速度运行 512 个端口的用例,并考虑在 Clos all-to-all 拓扑脊/叶中有多少个交换机跃点,这将是非常有趣的网络可以被淘汰。但我们怀疑,如果许多客户迁移到服务器上的 200 Gb/秒端口,他们会对 12:1 压缩感到满意。像这样: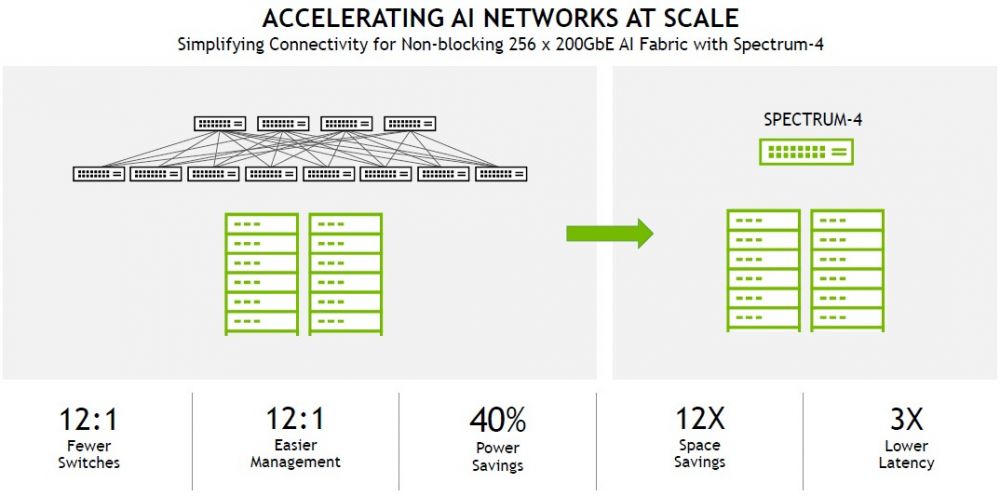
使用 Spectrum-4 连接 256 台服务器意味着所有机器彼此相距一跳。要将相同的 256 台服务器与 Spectrum-3 交换机连接起来,将需要 12 倍的交换机来构成脊/叶网络,并且在交换机结构上的服务器之间平均需要三跳,从而将网络延迟增加 3 倍。
Spectrum-4 芯片和交换机的定价尚未确定,但 Nvidia 将像 Mellanox 一样销售完整的交换机和 ASIC。定价的经验法则是,对于任何给定的代际跳跃,每个端口的带宽增加 2 倍,每个端口的成本增加 1.5 倍至 1.6 倍。看起来 Nvidia 正在跳过 25.6 Tb/秒的 ASIC 一代,这应该意味着 800 Gb/秒的端口应该运行在 1,800 到 2,000 美元左右,这与 2015 年 100 Gb/秒端口开始时的 100 Gb /sec波首先开始构建。这也与 400 Gb/秒端口目前以接近 1,000 美元的价格运行的事实一致。
Nvidia Spectrum-4 交换机推出的最后一项重大新技术是自适应路由和使用 RoCE 协议改进服务器节点之间的直接内存访问,这是对 RDMA 直接内存访问的重复,它提供了 InfiniBand(Mellanox 和现在Nvidia冠军)如此低的延迟。
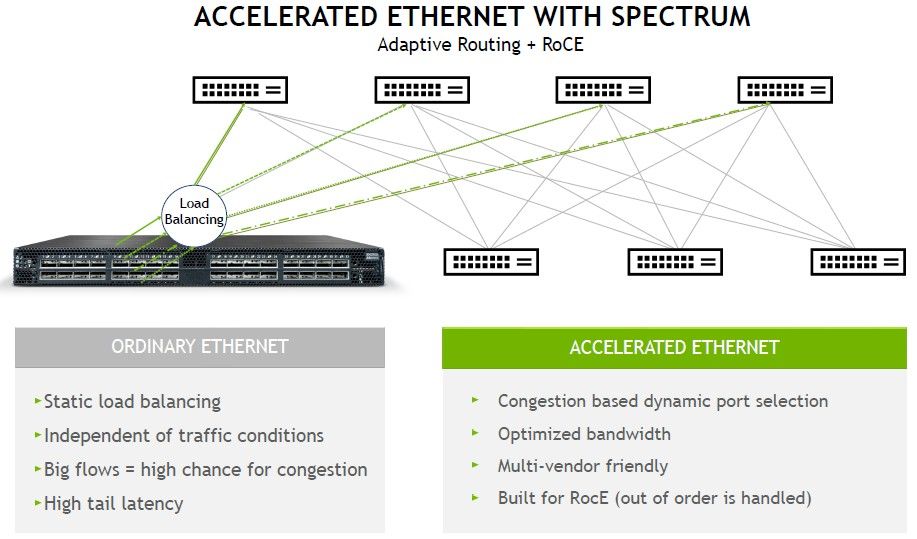
自适应路由很重要,特别是对于 AI 训练工作负载和分布式数据库——Mellanox 在那些不想使用 InfiniBand 的人中使用 Spectrum ASIC 获得牵引力的地方。
“我们已经了解了很多关于人工智能和数据库的知识,”Deierling 解释道。“在传统的网络模型中,你有大量的 CPU 线程和大量要连接的套接字,并且网络上有大量的流量。在这里,您可以使用静态路由,例如 Equal Cost Mutli-Path 或 ECMP 路由。一切正常,因为这些是鼠标流,应用程序确实不需要交换大量数据。但是对于 AI 和数据库工作负载,它们确实如此,并且您会得到这些大流量,而对于大流量,您需要更加小心。我们确定大流量发生在哪里,并确保不会在同一链路上发送太多流量,因此我们实现了最佳带宽,因此这些巨大的工作负载可以大规模运行。”
Deierling 表示,这种自适应路由技术源自 InfiniBand 自己的自适应路由,它从一开始就拥有这种路由技术,并且之所以成为可能,是因为 InfiniBand 是“在它很酷之前是软件定义的网络”,并且正在被添加到其以太网产品中两家超大规模企业和云建设者的要求。我们强烈怀疑其中之一是微软,它是 Nvidia InfiniBand 的大客户,但另一个可能是谷歌。
这就是我们这么认为的原因。Spectrum-4 交换机中的另一个新功能是一种称为超精确计时的功能,它实现了精确时间协议,这在大规模分布式数据库中是必需的。使用网络时间协议,它已经在网络中使用了 35 年,您能做的最好的事情是大约 10 毫秒到大约 1 毫秒的同步。任何需要比这更细粒度的东西都需要其他一些计时机制——例如,谷歌在其数据中心使用原子钟来同步其 Spanner 分布式数据库中的数据读写. 借助 Spectrum-4 ASIC 中的超精确计时功能,数据流可以以低至数十纳秒的精度进行标记,这足以跟踪对数据库的写入顺序并确保读取数据部分在写入完成后完成。
这种基于网络的细粒度数据同步对于所有使用或销售大规模数据库的超大规模企业和云建设者以及在基础设施上运行它们或将它们用作这些超大规模企业和云服务的客户来说都是必要的建设者。但看看英伟达能否赢得与谷歌的网络交易将会很有趣。
工作时间:早上9:00-下午6:30
河南快米云网络科技有限公司
 公安备案编号:41010302002363
公安备案编号:41010302002363
Copyright © 2010-2023 All Rights Reserved. 地址:河南自由贸易区开封片区经济开发区宋城路122号