

对 Gerrit Kazmaier 来说,托管数据库和数据湖之间的区别从来没有多大意义,而如今,随着数据堆积如山,被构造力推高,这种区别就更没有意义了。
“这种区别从来没有用过,”谷歌云数据库、数据分析和 Looker 总经理 Kazmaier 本周在与记者和分析师的虚拟会议上表示。“这是技术上的必要性,因为数据量一直在增长,而且在传统数据存储技术中管理它们变得过于复杂且成本过高。”
随着数据量的增加,组织转向数据仓库。随着数据量的进一步扩大——以及更高比例的非结构化数据——他们开始引入数据湖来完善他们的数据仓库。
“这产生了以相对较低的成本在不同的仓库中大规模存储大量数据的强烈需求,”Kazmaier 说。“这是数据湖运动的入口。但它付出了巨大的代价。对于所有这些试图在数据之上进行创新但最终发现它只是一个数据沼泽的组织来说,这付出了一致性、安全性和可管理性的巨大代价。”
它还在企业必须管理的 IT 环境中创建了单独的数据孤岛,这是其他供应商(从Hewlett Packard Enterprise和 Dell Technologies 到Pure Storage和Hitachi Vantara)正在努力解决的问题。今年早些时候,我们写了一家名为 Onehouse 的初创公司,该公司从隐身中脱颖而出,计划利用开源 Hudi 将数据库和数据仓库功能引入数据湖,创建可以容纳和管理结构化、半结构化和非结构化的 Lakehouse数据。
谷歌云正在寻求做类似的事情。在本周的数据云峰会上,该公司推出了 BigLake,它统一了数据仓库和数据湖,使组织能够通过单个数据副本存储、管理和分析其数据,而无需复制或移动数据或担心底层存储格式或系统。
BigLake 将 Google Cloud 的 BigQuery 数据仓库功能扩展到 Google Cloud Storage 上的数据湖,使用 API 接口对 Google Cloud 和开放格式(如 Parquet)和开源处理引擎(如 Apache Spark)进行更大的访问控制。它消除了 Kazmaier 所说的“托管仓库和数据湖之间的人为分离”。
BigLake 提供预览版,是 Google Cloud 在此次活动中推出的众多新产品和增强功能之一,这些产品和增强功能利用了该组织多年来通过 BigQuery、Vertex AI等数据工具所做的工作——一个集合使企业能够构建和管理机器学习工作负载的服务——Spanner 分布式 SQL 数据库管理和存储服务以及 Looker 商业智能平台。
所有这些以及数据库迁移计划等新产品及其合作伙伴计划中的更新旨在使企业能够更轻松地从他们创建的海量数据中获得更大的商业价值。谷歌云是全球第三大云提供商,约占全球收入的 10%,落后于亚马逊网络服务(约 33%)和微软 Azure(约 22%)。
解决数据挑战——不仅是存储和管理数据,还包括移动、处理、分析和保护数据——可以帮助 Google Cloud 继续加速其多年努力,以在企业中获得更大的影响力。市场研究公司 Statista 预测, 2025 年将创建超过180 泽字节的数据。
Kazmaier 说:“数据几乎是这个星球上每个高管的首要议程。” “我们相信,要转型,你实际上不能应用过时的技术、过时的架构和过时的想法来解锁真正拥有的无限潜力数据。…今天的数据是多格式的,它是流式的,并且是静止的,它跨越数据中心,甚至跨越今天的云。数据架构需要将所有这些结合在一起。”
Google Cloud 能够使用 BigQuery 等服务构建它在数据存储领域已经完成的工作,从而构建 BigLake。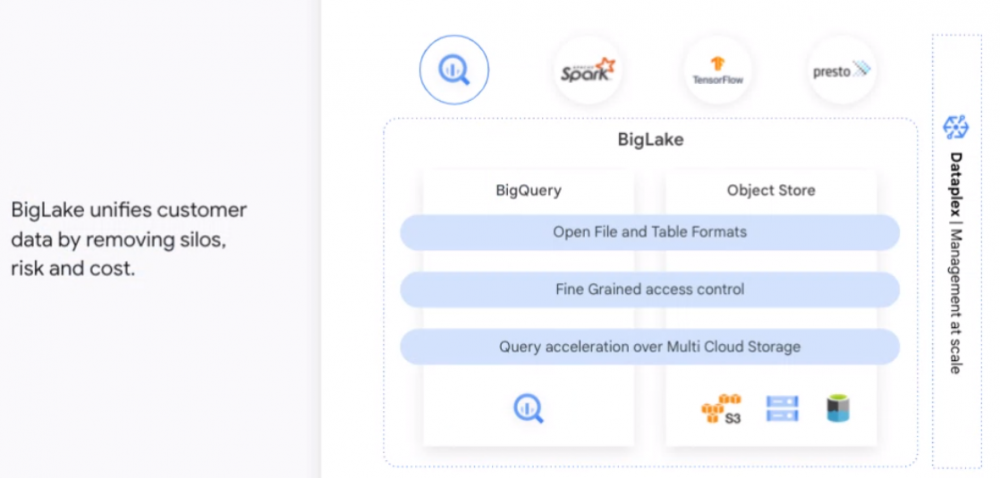
“我们在 BigQuery 上拥有数以万计的客户,我们在所有治理、安全性和所有核心功能方面投入了大量资金,”他说。“我们正在从 BigQuery 中汲取创新,现在将其扩展到所有不同格式的数据,以及湖泊环境中,无论是在带有 Google Cloud 存储的 Google Cloud 上,还是在 AWS 上还是在 Azure 上。我们采用创新并将其扩展到其他数据湖环境。”
与 BigLake 一起,Google Cloud 很快将使数据工程师能够实时跟踪其 Spanner 数据库中的变化。即将推出的 Spanner 更改流可跟踪整个数据库的插入、更新和删除。这些更改可以复制到 BigQuery 以推动分析并存储在 Google Cloud Storage 中以确保合规性。
Vertex AI Workbench 现已上市,它为数据和机器学习系统创建了一个单一界面,为用户提供了一个用于数据分析、数据科学和机器学习以及直接访问 BigQuery 的通用工具集。Google Cloud 上云 AI 和分析服务副总裁 June Yang 表示,Workbench 还与 Serverless Spark 和 Dataproc 集成,使组织能够以比传统系统快五倍的速度构建、训练和部署机器学习模型。

此外,谷歌云还拥有 Vertex AI 模型注册表,这是一项预览服务,可让数据科学家更轻松地共享模型,并让开发人员更快速地将数据转化为预测。
Connected Sheets 和 Data Studio for Looker 是 Google Cloud 将其商业智能服务组合更紧密地整合在一起的过程的一部分。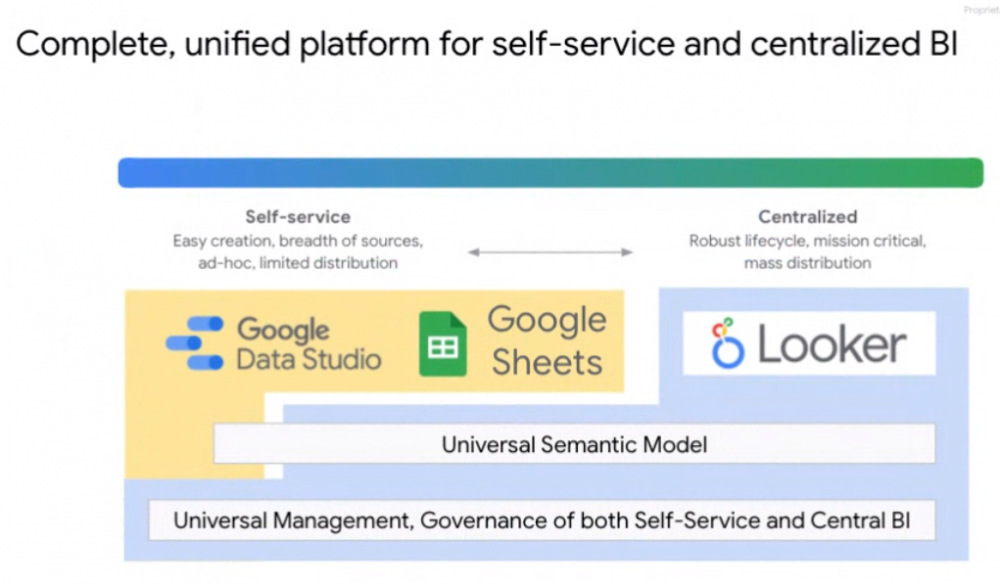
“我们将这两个世界结合在一起,”谷歌云产品管理总监 Sudhir Hasbe 说。“现在您可以使用 Data Studio 或 Tableau 等工具的自助服务功能,并使用 Looker 语义层的中央模型,您可以在一个地方定义您的指标,所有自助服务工具将无缝地工作和互动那。这将使组织和高级用户能够拥有自助服务工具,而且还可以集中指标并对整个组织的业务有一个共同的理解。”
如果 Google 最终成为超大规模和云构建者中 X86 架构的坚定支持者,这不是很有趣吗?
亚马逊网络服务过去几年一直在推动其 Graviton 产品线,自去年 3 月以来一直在生产 Graviton2,并且仍在预览其 Graviton3 芯片,该芯片于去年 11 月推出,但尚未全面生产——这意味着与提要、速度和价格——跨 AWS 区域和数据中心。
现在,微软正在通过 Azure 云上的新实例进入游戏,同样处于预览阶段,这些实例基于 Ampere Computing 制造的 80 核“Quicksilver”Altra Arm 服务器芯片,该芯片于两年前首次亮相2020 年 6 月,多达 80 个内核以 3 GHz 的最高速度运行。尽管本周关于使用这些 Ampere Computing Altra 处理器的新 Azure D 系列和 E 系列实例引起了很多争论,但奇怪的是为什么微软一年前——甚至更早——没有提供这些,以及为什么它是也没有部署 128 核的“Mystique”Altra Max 后续产品,这些产品原定于 2020 年第四季度提供样品,并于去年秋天开始供货。对微软来说,好消息是 Mystique 处理器与它现在部署的 Quicksilver 芯片的插槽兼容,因此它可以得到它们,它可以将 Altra Max 芯片融入其供应链、服务器和它的数据中心。

我们不期望未来的“Siryn”芯片,它可能不使用 Altra 品牌,并且基于我们称之为“A1”的本土核心,因为 Ampere Computing 不了解人们需要代号和最终产品名称,所以他们可以有效地谈论正在开发和交付的技术。(一两个同义词对读者和作者来说都是一件美好的事情。)在我们去年 5 月的安培计算路线图故事中,我们指出超大规模企业和云建设者购买的是路线图,而不是单点产品,甲骨文、腾讯、阿里巴巴等公司,现在微软正在为他们的公共云购买,因为他们相信 Ampere Computing 将获得下一代芯片,我们称之为“Polaris”,在没有名字的情况下,并有一个新的 A2 内核可以启动,正如预期的那样,在 2023 年推出.
仅仅因为 Ampere Computing 推出了它并不意味着它可以立即大量出货,或者超大规模和云构建者可以立即将 100,000 台机器放到他们的云中。量产、认证和建设都需要时间,而数据中心的这些阶段性变化将需要五到十年的时间才能成为实质性的。但是我们没有理由认为 Arm 服务器芯片无法达到 Arm Holdings 很久以前设定的 20% 到 25% 的目标——前提是一切运行良好。
微软毫不掩饰其希望看到 Arm 服务器芯片在 Azure 云上代表其大量容量的愿望——2017 年开放计算峰会的一次演讲称,目标是让 Arm 服务器成为服务器计算容量的 50% ——但微软没有承诺在 Azure 的基础设施云部分上提供 Arm 服务器(与用户购买 Microsoft 软件的访问权限而不是原始容量的平台和软件云部分相反),它同样没有承诺提供 Windows Server 堆栈在 Arm 上(尽管它在内部将 Windows-on-Arm 用于托管在 Azure 上的本土应用程序)。当微软在 2017 年同一场 OCP 峰会上公布其“奥林巴斯项目”设计时,Cavium ThunderX 服务器芯片和 Qualcomm Centriq 服务器芯片都在这些服务器上进行了预览。但高通取消了 Centriq 的插头,Marvell 收购了 Cavium,一段时间后取消了 ThunderX3 的插头。这让微软不得不选择设计自己的 Arm 服务器芯片或帮助 Ampere Computing 建立自己。(我们中的许多人认为微软最终会两者兼得。)
想知道在 Azure 中部署了多少 ThunderX2 铁(我们的猜测不是很多,否则 Marvell 会继续运行),以及现在 Azure 中有多少 Ampere Computing Altra 设备(我们的猜测可能更多)。微软正在基础设施云上提供 Arm 容量——在 VM 内运行 Linux 操作系统,但据我们所知,Windows Server 不支持,但这种情况也可能发生变化——这一事实意义重大。我们需要将此视为一桩桩桩桩事,以及微软的一份声明,即它不会让 AWS 完全靠其孤独来定义数据中心中 Arm 服务器的未来。
因为这些 Quicksilver Arm 实例处于技术预览阶段,所以我们对它们的了解比我们希望的要少得多,但是一旦它们退出预览版以及 AWS Graviton3 实例退出预览版,您就可以赌比尔盖茨的最后两美元和 Jeff Bezos,我们将进行价格/性能分析,比较这两种类型的 Arm 服务器实例以及 X86 熨斗这些大型云(世界上最大的两个云)的销售情况。事实上,我们构建了电子表格来进行比较,假设现在可以使用提要、速度和价格。值得称赞的是,微软已经公布了它推出的六种 Arm 服务器实例类型和一些基本的显着特征:
首先,每个芯片有 8 个 DDR4 内存控制器,Altra CPU 可以拥有比微软配置的更多的内存。Altra CPU 还支持 NUMA 集群,以创建更大的内存地址空间和计算引擎。目前尚不清楚这些 Azure 实例是基于单插槽设计还是双插槽设计。
我们想知道的第一件事,但微软没有回答,为什么当 Altra 芯片达到 80 核时,这些实例达到 32 核和 64 核?可能是它们是单插槽服务器,并且它们位于没有 DPU 来卸载网络和存储虚拟化的系统中,因此一些内核正在运行管理程序堆栈时被烧毁。可能是 Microsoft 服务器中有一个 DPU,而 32 核和 64 核部件是 Ampere Computing 在数量和价格方面的最佳选择。不管它是什么,没有一直运行它是有原因的,它是这两种情况之一。(或者,如果在 Arm 上运行的 Hyper-V 虚拟机管理程序确实效率低下,则可能两者兼而有之。)
为了帮助了解不同 Azure Arm 服务器实例 SKU 的方式,我们汇总了这张表,其中包括按需实例的每小时成本。(现货定价也可用,但我们发现这作为跨云的通用指标不太有趣。)只是为了好玩,并让您了解运行这些实例的成本,只要物理服务器倾向于保留在超大规模和云数据中心,我们计算了三年内实例的成本。我们最终将以此作为跨云和云内价格/性能比较的基础。(如今,对于云中的服务器寿命而言,四年可能更准确。)

Azure 上的价格与虚拟 CPU 或 vCPU 的数量成线性关系,至少在此产品线中是这样。底层芯片的成本可能不会——每个实例在任何给定工作负载上的绝对性能也可能不会线性扩展。因此,不要假设价格/性能在各个实例中是恒定的。事实并非如此,正如我们去年这个时候展示的那样,AWS 与去年的 Graviton2 和 X86 实例当然也没有进行比较。
据微软称,Azure 上的 Dpsv5 系列实例旨在运行 Web 服务器、应用程序服务器、Java 和 .NET 应用程序、开源数据库以及游戏和媒体服务器。Dpsv5 实例的每个核心有 4 GB,没有本地磁盘,而 Dpdsv5 实例的每个核心有 4 GB 和随核心扩展的本地存储。Dplsv5 实例每个核心有 2 GB,Dpldsv5 实例相同,但具有本地存储。所有这四种实例类型都从 2 核扩展到 64 核。Epsv5 实例每个核心有 8 GB,但只能扩展到 32 个核心,并且 Epdsv5 实例添加了本地存储。(如果你能保持这些名字直截了当,对你有好处。)
没有本地存储的实例成本更低,并且 Microsoft 在 Azure 上提供的所有不同外部闪存存储选项都可用于这些 Arm 实例。这些实例有 2 到 8 个网络接口。微软表示,它提供“高达 40 Gb/秒”的网络连接,而且必须以某种方式为每个虚拟 NIC 提供。虚拟 NIC 的数量可能与每个虚拟 NIC 的带宽成反比,我们猜测每个物理服务器的管道只有 100 Gb/秒。但如果有两个以太网端口,它可能是 200 Gb/秒。我们会看到的。
这里有一件很重要的事情,我们已经与安培计算多次讨论过这个问题,并且从 AWS 那里听到了关于 Graviton 系列芯片的同样的话:一组具有静态时钟速度的真实内核优于一组虚拟内核在确定性性能方面具有可变的时钟速度。
使用 Ampere Computing Altra 芯片,没有同时多线程,或简称为 SMT,因此 vCPU 是实际的 CPU 内核。当谈到 Altra 时钟速度时,它们被锁定在一个速度上,并且没有这种可变的时钟速度取决于在任何给定时间使用的内核数量。云的前提是服务器以无数种方式与一百万客户进行分割,并且每个核心都保持忙碌,因此长时间超频一个或一组核心的机会不大,因为新的工作负载会现在随时来。Ampere Computing 的设计点——这是在听取了超大规模和云建设者的意见之后——是让 CPU 更具确定性。这意味着保持时钟速度恒定,而不是在内核上使用可能导致争用的虚拟线程。
请注意,并非总是如此,这也很重要。对于 HPC 工作负载,通常会关闭 SMT,因为管理虚拟线程的开销实际上会降低整体性能。对于喜欢大量线程的工作负载(例如,事务处理监视器和关系数据库),在内核缓存之间没有太多争用的情况下,可能会发疯。根据我们多年来看到的轶事证据,对于 HPC 风格的工作负载、英特尔的超线程或 HT,SMT 的实施可能会导致性能下降 10% 到 20%。另一方面,在 Power E1080 服务器中采用 IBM 的“Cumulus”Power10 处理器。一个全口径,根据 IBM 的 rPerf 基准测试(TPC-C 在线事务处理测试的 I/O 未绑定变体),240 核系统的相对性能为 2,250.8,每个核激活一个线程。随着虚拟线程的开启——每核 2 个,然后是 4 核,然后每核 8 个——性能扩展了 2 倍、2.8 倍和 3.6 倍。(那个 SMT4 跳转不如 SMT8 跳转。)
关键是,SMT 的影响是复杂的,每个使用 X86 Iron 的云都会在很多实例上打开它——我们不确定它是否通用——以提高其 vCPU 的粒度。它为他们提供了更小的切片和更多的 SKU,并且他们可以使使用中间 bin X86 CPU 的服务器看起来比实际更大。如果他们在 SMT 运行时告诉客户,那就太好了,如果他们不想要它,如果它给他们一个裸机选项,那就更好了。(许多人只是出于上述原因。)
现在,让我们谈谈性能。在宣布基于 Arm 的 Azure 实例的博客文章中,Azure 计算平台产品负责人 Paul Nash 表示:“新的 VM 系列包括通用 Dpsv5 和内存优化的 Epsv5 VM,可提供高达 50%比基于 X86 的 VM 具有更好的性价比。”
这种说法相当模糊,术语是“性价比”,因为它是一个部门,而不是一个产品。所以我们修正了上面的微软报价是准确的。
无论如何,微软的声明并没有告诉我们太多关于性能或价格/性能的具体信息。
Ampere Computing 的首席产品官 Jeff Wittich 的这一声明使球向前推进了一点:“Ampere Altra VM 的性能分别比同代同等大小的 Intel 和 AMD 实例高出 39% 和 47%。*除了是作为高性能选择,Ampere Altra 处理器非常节能,直接减少了用户的总体碳足迹。”
上面的星号导致的脚注是这样说的:“基于 est. SPEC CPU 2017 Integer Base for D16ps v5, D16s v5, D16as v5 Azure VMs running on Ubuntu 20.04 LTS andcompiled with gcc 10.2.1, -O3, -mcpu=本地人,JEMalloc”
更接近了,但仍然不令人满意。SPECrate 是 CPU 通常用来衡量的吞吐量整数测试。(有一个基本结果,这意味着所有 SPEC 模块都使用相同的编译器标志进行编译,还有一个峰值结果,即使用任何编译器选项使其尖叫。)测试人员运行 SPEC 测试的多个副本并查看有多少事务吞吐量他们可以通过芯片。通过 SPECspeed2017 测试,套件中每个基准测试的一个副本以一系列方式运行,测试人员可以根据 OpenMP 选择使用多少线程,结果是时间的度量——完整的单运行测试。
我们联系了 Wittich,表达了对这种变幻莫测的失望,他向我们提供了在Ampere Computing 发布的关于 Azure 实例的简短博客中的比较参考之一中使用的实际数据:

下表汇总了这些实例的原始 SPECrate2017 整数性能,这些实例基于 AMD、Intel 和 Ampere Computing 的最新 CPU,以及这些实例的每小时成本。由于两组数字的相对大小,Wittich 将性能除以成本,这告诉您在这三组中花费多少 SPEC Integer 吞吐量。

上表有一个错字,只是为了说明这些 Microsoft 实例名称的难易程度。测试的是 Altra D16psv5 实例,而不是 Altra D16pdv5。(后者有 600 GB 的闪存,而且成本更高。)
我们喜欢考虑每单位性能的成本,而不是每单位资金的性能,因此我们翻转数据并计算了 Ampere Computing 使用 SPEC 的整数率测试的三个不同实例的三年成本(无折扣)测试:

我们认为,如果您打算长时间使用云上的实例,这可以让您更好地了解它的成本。您得到的百分比与 Wittich 计算的相同。现在,如果您可以关闭 AMD 和 Intel 芯片上的 SMT 会发生什么?好吧,如果您正在考虑虚拟 CPU 数量,那么以一种思考方式,您将不得不购买两倍大的 AMD 和 Intel 实例。他们将有 16 个核心,这些核心会更强大,并且会做更多的工作。但这不是衡量标准,真的。
我们认为更合理的做法是退回到 AMD 和 Intel 芯片上的 8 个真实内核,并将性能提升 10% 到 20% 之间,看看会发生什么物有所值。如果这样做,那么 AMD “Milan” Epyc 7003 实例的 SPECrate Integer 性能将介于 50.8 和 55.4 之间,而 Intel “Ice Lake” Xeon SP 实例的 SPECrate Integer 性能将介于 53.7 和 58.6 之间。Altra 实例的价格仍然较低——比 Milan 低 10.5%,比 Ice Lake 低 19.8%——而且性能仍然更高——比 Milan 高 23% 到 34.2%,Ice 高 16.5% 到 27%湖。因此,Altra 芯片的性价比优势仍然很显着——一般来说,每单位性能的成本要低三分之一左右。
正如Google 七年前告诉我们的那样,它愿意改变 CPU 架构以获得可持续的 20% 的性价比优势。
最后一件事。Microsoft 在 Arm 实例上支持 Canonical Ubuntu Linux、CentOS 和 Windows 11 专业版和企业版,接下来将支持 Red Hat Enterprise Linux、SUSE Linux Enterprise Server、Debian、AlmaLinux 和 Flatcar。没有提到 Windows Server。
我们期待看到 AWS Graviton 和 Azure Altra 实例的性能数据,并看到这一切如何发挥作用。这是十多年前应该发生的事情。真正的竞争,不止一个方面。
马萨诸塞州尼德汉姆,2022 年 4 月 6 日——许多组织正在积极开展边缘之旅,因为他们寻求以新的方式与客户建立联系、提高运营效率并采用数字技术来支持创新。国际数据公司 ( IDC ) 的 EdgeView 2022 调查发现,四分之三的组织计划在未来两年内增加其边缘支出,平均增幅为 37%。
多种因素共同推动了边缘支出的增加。扩展工作负载和利用人工智能 (AI) 和机器学习 (ML) 的新用例的性能要求需要更大的边缘计算能力。此外,存储在边缘位置的数据量正在迅速扩大,组织计划将这些数据保留更长时间。因此,部署在边缘的物理服务器数量正在增加。大部分投资优先考虑边缘位置现有基础设施的现代化,而不是建设新的基础设施。
调查还发现,部署边缘的企业高度专注于建立可扩展的业务,其投资可以迅速为盈利做出贡献。边缘部署的首要目标是增加收入、改进产品和服务以及降低成本。但边缘部署也提供了填补利基市场或破坏现有市场的重要机会。
IDC 负责云和边缘基础设施服务的研究副总裁 Dave McCarthy 表示:“企业正在发出信号,他们希望从云运营模式中获得好处,并可以在任何地方自由部署。” “这为技术供应商创造了巨大的机会,可以在这些分布式环境中降低复杂性并保持一致性。”
Edge Strategies 研究总监 Jennifer Cooke 说:“边缘基础设施部署正在将 IT 重新转变为在组织内更具战略性和影响力的角色。“IT 组织正在推动和支持更广泛组织内的关键数字优先工作。”
EdgeView 2022 调查的其他主要发现包括:
组织将边缘解决方案与传统基础设施集成的能力列为关键选择标准,并认为它与边缘决策中的价格一样重要。但是,边缘管理策略并未与云和核心紧密集成,这表明组织在寻求将核心、云和边缘资源作为一组有凝聚力的灵活资源来利用时,可能需要修改其管理策略。
组织将继续在边缘部署和支持许多不同的计算、存储和网络架构。能够在多个环境中部署也是一个关键的选择标准,强调了组织将计算资源扩展到许多不同类型的环境的持续计划,包括云和核心数据中心以及现场。
出于必要并且由于需要利用云资源,边缘将继续成为云、托管、现场位置和公司拥有的数据中心的广泛组合。在接下来的两年中,预计三分之二的组织将更多地转向公共云资源。但总的来说,所有边缘类型都会增加。
关于设备所有权,大多数人表示他们的组织更愿意保留基础设施的所有权。这将推动对灵活消费模式的更大需求,这些模式具有云的运营成本优势以及更大的基础设施所有权和控制权。
此项研究可通过 IDC 的IDC EdgeView研究服务获得,该服务是IDC BuyerView实践的一部分。IDC 的 EdgeView 2022 调查使技术组织、硬件供应商、软件开发商、服务供应商和投资者能够更好地了解其客户的购买意图,并帮助制定战略和解决方案,解决当前和新兴的边缘技术和工作用例。这包括概述将基础架构和应用程序部署在更靠近数据生成和使用的地方的主要动机,并探索延迟、成本、弹性、安全性和合规性等方面。
关于 IDC
国际数据公司 (IDC) 是为信息技术、电信和消费技术市场提供市场情报、咨询服务和活动的全球首屈一指的供应商。IDC 在全球拥有 1,200 多名分析师,在 110 多个国家/地区提供有关技术、IT 基准测试和采购以及行业机会和趋势的全球、区域和本地专业知识。IDC 的分析和洞察力可帮助 IT 专业人士、业务主管和投资界做出基于事实的技术决策并实现其关键业务目标。IDC 成立于 1964 年,是全球领先的科技媒体、数据和营销服务公司International Data Group ( IDG )的全资子公司。
伦敦,2022 年 4 月 6 日——考虑到零售商和 CPG 公司处理来自不同接口和业务功能的大量非结构化和碎片化数据的快速变化的环境,数据准确性至关重要。对于旨在实现大规模实时上下文客户体验的公司而言,集成数据孤岛和利用 AI/ML 分析仍然是基础。
在消费行业,打破数据孤岛并遵守安全标准和法规是实施客户体验流程时面临的最大挑战之一。IDC 预测,“到 2024 年,用于推动个性化体验和改进全渠道营销、营销和服务智能的客户数据中,有 25% 将来自共享客户数据中心”(参见 IDC FutureScape:2022 年全球零售预测— IDC #US47249621,2021 年 10 月)。
IDC Retail Insights 旨在帮助零售商和 CPG 公司选择全球客户数据平台软件和专业提供商。IDC 新的全球零售和 CPG 客户数据平台软件供应商 2022 供应商评估 MarketScape评估主要企业软件供应商和专业 CDP 供应商在满足全球零售和 CPG 公司和品牌跨行业(食品和非食品)需求方面的能力和战略零售)。供应商根据他们在设计、开发、安装、配置和维护为零售商和 CPG 公司服务的完整客户数据平台的演进方面取得的成功进行评估。
该研究评估了 13 家供应商:Adobe、Algonomy、Amperity、BlueConic、Microsoft、mParticle、Optimove、Redpoint Global、Salesforce、SAP、SAS、Tealium 和 Treasure Data。供应商会根据一系列能力进行评估:
客户身份和隐私管理
零售和 CPG 特定服务和用例
CDP核心能力和功能
解决零售和/或 CPG 特定需求的外部合作
支持和培训服务
软件部署和支持
关于 IDC MarketScape
IDC MarketScape标准选择、权重和供应商分数代表了经过深入研究的 IDC 对市场和特定供应商的判断。IDC 分析师通过结构化的讨论、调查和与市场领导者、参与者和最终用户的访谈来定制衡量供应商的标准特征范围。市场权重基于每个市场的用户访谈、买家调查和 IDC 专家的意见。IDC 分析师基于对供应商的详细调查和访谈、公开信息和最终用户体验,对各个供应商的评分以及最终供应商在 IDC MarketScape 中的排名进行评估,以努力对每个供应商的特征、行为、和能力。
富士通已确认将通过新兴的云服务开放对支持全球顶级超级计算机“Fugaku”的相同系统架构的访问。
新的富士通计算即服务(CaaS)产品组合还将为希望探索人工智能和机器学习的量子模拟资源和服务的用户提供挂钩。
首先是富士通云服务 HPC,该公司从今天开始接受预订,预计 10 月份上市。
富士通表示,它将首先开始服务日本市场,随后将在全球范围内推广到包括欧洲、亚太地区和美洲在内的国际地区。
随后将提供访问富士通 Digital Annealer 技术的服务,该技术使用量子退火过程来寻找复杂问题的最佳解决方案,以及人工智能和机器学习服务。
富士通云服务 HPC 包括富士通 PRIMEHPC FX1000的计算能力,该计算能力基于 Fugaku 超级计算机中使用的相同 A64FX 64 位 Arm 芯片,根据TOP500 列表,该超级计算机仍然保持着世界上最快的桂冠。
PRIMEHPC FX1000 中的每个节点都围绕单个 48 核 A64FX 芯片构建,32GB HBM2 内存直接堆叠在芯片顶部,声称内存带宽为 1,024GB/s。PRIMEHPC FX1000 每个机架最多支持 384 个节点,由富士通自己的 Tofu D 高速结构互连。
据富士通称,HPC 服务将包括支持以及一套软件和库,以帮助客户部署 HPC 应用程序。它还将提供性能调整和应用程序分析服务,以支持专注于研究和分析的客户。
富士通表示,计算节点、登录节点、作业调度程序、存储和 HPC 应用软件都将提前配置,这意味着用户不必构建自己的 HPC 环境,只需要准备数据进行分析。用户只需为他们需要的资源付费。
富士通表示,订阅者使用富士通云 HPC 服务的方式是通过每月的“HPC 预算”,计算资源将按现收现付的方式消耗。
富士通告诉我们,最初将针对使用 HPC 节点所需的 HPC 预算制定三种定价计划,具体取决于周围使用的存储容量等条件。这些是每月 50,000 日元(约 400 美元)、每月 500,000 日元(约 4,000 美元)和每月 100 万日元(约 8,000 美元)。这些是日本初始服务的价格。
富士通似乎热衷于支持没有先前 HPC 知识或经验的客户,以通过专业的运营和技术支持帮助他们从云服务中受益,并根据个人客户的业务计划制定 HPC 使用计划。
富士通还表示,它的目标是在富士通云服务 HPC 与其 Fugaku 超级计算机之间实现高度兼容性,以便将 Fugaku 上产生的研究成果轻松地转移到 CaaS 服务中,以加速实际应用。相反,富士通还设想用户计划大规模分析和研究项目,以便在必要时能够将他们的应用程序迁移到 Fugaku。
据其计算科学中心主任松冈聪(Satoshi Matsuoka)称,这是日本RIKEN 研究所的科学家正在与富士通合作实现的一项能力。
“我们正在与富士通合作,使其 CaaS 与 Fugaku 高度兼容,以支持这些要求,我们希望 CaaS 成为快速将 Fugaku 的研发与工业用途和社会实际实施联系起来的重要服务,”他在一份声明中说。
“展望未来,我们将与富士通合作,将 Fugaku 与这项新服务进一步协同,以在云中无缝提供其功能。”
在这方面,富士通云服务 HPC 不同于其他一些 HPC 即服务产品,例如联想的TruScale和 HPE 的GreenLake for High Performance Computing,两者都在客户自己的数据中心或托管站点中提供物理基础设施,但作为托管服务。
对于企业而言,另一种选择是与云服务提供商合作,正如我们的姊妹网站The Next Platform所讨论的那样,AWS、Azure 和 Google Cloud 都提供 HPC 功能。然而,这些通常要求客户通过单独的服务自行组合和管理解决方案,而富士通则提供支持服务作为交易的一部分。
Hyperion Research 的 HPC Market Dynamics 高级顾问 Steve Conway 表示,富士通的举动并非史无前例,而且已经有各种各样的 HPC 服务。
“富士通基本上只是加入了人群,”他说。
然而,更大的图景是,日本政府正在推动富士通将其超级计算机的可用性扩展到国内市场之外。“日本试图跟上超级计算领导者的步伐,他们做得很好,但它主要服务于国内市场。现在政府已经下令向非日本研究人员开放,”康威说.
富士通的 K5 混合云服务作为公共、私有虚拟或私有托管服务进行销售和部署,直到2018 年在除日本以外的世界所有地区被彻底淘汰。从那时起,它对员工进行了培训,使其在 AWS 和Azure公有云方面更加熟练
DevOps 装备 CircleCI 一直在遭受性能问题的困扰,这一问题已经持续了一天的大部分时间,开发人员正在等待平台重新上线。
该服务密切关注 GitHub 和 Bitbucket 之类的内容,并在提交时启动构建。然后它会测试构建并在出现问题时发出通知。该平台还具有托管云服务。
然而,今天的事情有点出岔子。CircleCI将这个问题描述为“性能下降”,这始于“数据库读/写延迟”。与此同时,在 Twitter 上,随着用户变得越来越焦躁,该公司推出了乐高抽奖活动。
随着时间的推移,该公司在寻找根本原因时将情况升级为“事件”。
到下午,它告诉用户:“我们正在应用更改以确保构建正常运行。感谢您对我们的支持。”
在发布时,它已经“部署了一些缓解措施以通过我们的系统获得更多工作并继续致力于长期修复”,但开发人员仍在报告问题。
开发人员的问题在于,他们对破坏苹果购物车的代码更改太熟悉了,并且(通常情况下)有几个人在 Twitter 上发泄他们对这种情况的不满。
在停机 5 小时后开始查看代码和数据库更改是有意义的 🤷♂️
- Tamir Magen Tamir Magen (@tmgn66) 2022 年 4 月 6 日
CircleCI 的 DevOps 产品在 2011 年公司推出时最初仅限于作为纯云 SaaS,直到 2015 年的服务器产品到来时才提供自托管版本。
2019 年,这家软件测试和交付公司遭遇了涉及“第三方分析供应商”的安全事件。它当时表示,攻击者能够“不当地访问我们供应商帐户中的一些用户数据,包括与 GitHub 和 Bitbucket 相关的用户名和电子邮件地址,以及用户 IP 地址和用户代理字符串。”
它说,没有源代码、构建日志或其他生产数据处于危险之中,也没有任何身份验证或密码数据丢失。它表示将与供应商一起升级安全性。
The Register联系了该公司以了解当前的停电情况,并将在有回应时进行更新。
与此同时,(到目前为止)近一天的中断提醒人们注意云依赖的风险。CircleCI 并不是唯一一个会出现摇摆不定的服务(我们敢说 GitHub 及其困境吗?),但是当人们习惯了这样的工作时,就会更加强烈地感觉到它的失败。
尽管如此,还是有更多时间参加任天堂乐高比赛,是吗?®
更新添加
CircleCI 告诉The Register,该问题现已得到解决。如果不在论坛中,请告诉我们。
美国司法部今天披露了法院授权拆除命令和控制系统的细节,沙虫网络犯罪团伙用于指挥受其 Cyclops Blink 恶意软件感染的网络设备。
此举是继美国和英国执法部门于 2 月发布的联合安全警报之后,该警报警告 WatchGuard 防火墙和华硕路由器被破坏以运行 Cyclops Blink。这种僵尸网络恶意软件(此处为技术故障[PDF])允许远程控制设备以代表其策划者进行攻击。
此前,山姆大叔曾表示,沙虫团队为俄罗斯联邦的 GRU 间谍神经中心工作,该中心负责处理外国情报活动。
“法院授权清除俄罗斯 GRU 部署的恶意软件表明该部门致力于使用我们掌握的所有法律工具来破坏民族国家的黑客行为,”司法部国家安全部门的助理司法部长马修奥尔森说。
“通过与 WatchGuard 以及该国和英国的其他政府机构密切合作,分析恶意软件并开发检测和修复工具,我们共同展示了公私合作伙伴关系为我们国家的网络安全带来的力量。该部门仍然致力于以任何形式对抗和破坏民族国家的黑客行为。”
在 3 月 22 日法院授权的行动中,联邦调查局从“数千个”防火墙设备中删除了恶意代码,Sandworm 入侵这些设备作为 Cyclops Blink 僵尸网络的命令和控制系统 (C2)。这切断了网络工作人员与受感染设备上的机器人之间的通信。
但是,该操作并未访问全球数千台单独设备上的远程控制 Cyclops Blink 恶意软件。联邦调查局使用自动脚本记录了 C2 设备的序列号和恶意代码的副本。据司法部称,特工“没有从相关受害者网络搜索或收集其他信息”。
联邦调查局补充说,该行动也不涉及任何 FBI 与机器人设备的通信。
2 月 23 日,英国国家网络安全中心和包括 CISA、FBI 和 NSA 在内的几家美国机构发布了一份咨询,确定了 Cyclops Blink,这些组织表示,这看起来是 Sandworm 替代 VPNFilter。
读者可能还记得,VPNFilter是 2018 年针对路由器和存储设备的恶意软件。Sandworm 是实施了几次高调攻击的船员,包括 2015 年和 2016 年对乌克兰电网的网络攻击、2017 年的 NotPetya 以及同年的法国总统竞选电子邮件泄露。
在 2 月份的联合警报中,这些机构指出 Cyclops Blink 以 WatchGuard 和华硕硬件为目标。由于这些设备通常位于受害者网络的外围,它们使 Sandworm 能够针对这些网络中的计算机进行各种恶意活动,例如间谍活动或部署更具破坏性的恶意软件。
趋势科技的另一条警告表明,Cyclops Blink 试图将这些受感染的设备转变为 C2 服务器,以备将来攻击。
在政府发布安全公告的同一天,WatchGuard 发布了针对其设备的检测和修复工具,并建议客户立即部署这些工具以删除任何远程控制恶意软件。不久之后,华硕发布了自己的指南。根据司法部的说法,到 3 月中旬,大多数受感染的设备仍然感染了 Cyclops Blink。
这些充当机器人的 WatchGuard 和 ASUS 设备需要修补并清除恶意代码。
“该部门强烈鼓励网络防御者和设备所有者审查 2 月 23 日的公告以及 WatchGuard 和华硕发布的版本,”美联储建议道
Atlassian 的 Jira 和 Confluence 问题跟踪和协作服务已经为一些客户关闭了两天,并且中断仍在继续。
从 UTC 周二 0902 左右开始,Atlassian 的状态页面报告了影响客户使用 Jira Work Management、Confluence、Jira Service Management、Jira Software 和 Atlassian Access Cloud 的问题。
该公司在今天 1204 UTC 的最后一次更新中表示,这些问题仍在解决中。
“我们将继续为我们的一些 Jira Work Management、Jira Service Management、Confluence、Jira Software、Atlassian Access、Jira Product Discovery 和 Opsgenie Cloud 客户解决事件,”该公司的最新状态更新说。我们可以确认这不会影响所有客户,但仍然是 Atlassian 的重中之重,因为我们专门的 SME 团队 24/7 全天候工作,以尽快恢复网站。随着解决方案的进展,我们将提供更多细节。”
在撰写本文时,大约 1900 UTC,服务问题仍未解决。
时机再糟糕不过了:Atlassian 目前正在内华达州拉斯维加斯举办其Team '22 活动,公司主持人正在讨论“团队如何协作、推动数字化转型和推动文化变革”。Atlassian 的客户已经注意到这一巧合。
“在 Jira 和 Confluence 中断的第二天,看着@Atlassian 的高管们在#atlassianteam上兴奋地推销华丽的新产品,真是令人沮丧,”伦敦一家科技公司的交付主管 Joseph Clift通过 Twitter写道。“我希望他们只是将路线图装箱,专注于服务可靠性和提高现有产品的性能!”
Atlassian 标记 Bitbucket 和 Confluence 数据中心缺陷
Atlassian 警告 Confluence 存在严重缺陷
您需要在不停机的情况下将数百万个存储库转移到 AWS。如何?Bitbucket 工程主管告诉所有人
CircleCI 遭受“性能下降”数小时
根据 Atlassian 的服务水平协议,停机时间已超过 Premium 计划每年允许的 8 小时 45 分钟(99.9% 的正常运行时间),因此受影响的客户可能有权获得退款。
这或许可以解释为什么华尔街似乎没有留下深刻印象。自 4 月 5 日服务问题开始以来,Atlassian 的股价已从每股约 317 美元跌至发布时的约 287 美元。
据 Atlassian 称,超过 200,000 名客户使用其软件。其公开的价值观之一是“不要#@!% 客户”。
维护出错了
在通过电子邮件发送给The Register的一份声明中,Atlassian 将问题归咎于一个出错的脚本。
公司发言人说:“在执行例行维护脚本时,少数网站无意中被禁用,导致他们无法访问他们的产品和数据。”
“我们知道我们的客户依赖我们的产品来完成他们的工作,我们对由此造成的中断感到抱歉。我们正在 24/7 全天候工作,以使产品恢复完全可用。受影响的客户可以通过https:/ /support.atlassian.com/contact如果他们有任何问题或疑虑。”
Atlassian 还向所谓的少数受影响客户提供了更广泛的声明,表明可能需要几天时间才能恢复正常。
很抱歉,您的网站目前不可用。在运行维护脚本时,少数站点被无意中禁用。我们的团队立即发现了这一点,并一直在努力恢复产品数据和相关访问权限。一个专门的团队正在夜以继日地工作,以尽快恢复这些站点。
我们预计恢复工作将在接下来的几天内继续进行,并且我们正在积极估计您的网站何时可以再次提供给您。我们认为此时没有任何数据丢失。我们可以确认此事件不是网络攻击的结果,并且没有未经授权访问您的数据。
在我们努力恢复对您网站的访问时,我们将每 6 小时在此处提供更新,如果我们有重大更新,则更快。如果您有任何问题或疑虑,请联系我们。
如果这里有一个教训,那么如果您的云服务出现故障,那么在拉斯维加斯发生的事情可能不会留在拉斯维加斯。
据说,一个与哈马斯有联系的多产中东团队正在使用恶意软件和基础设施来瞄准以色列高级官员,并从 Windows 和 Android 设备上窃取敏感数据。
高级持续威胁 (APT) 组织——被一些人称为 APT-C-23、 Arid Viper、Desert Falcon 和 FrozenCell 等名称——发起了一场精心策划的网络间谍活动,花费数月时间推出虚假 Facebook 账户以针对特定潜在客户据 Cybereason 的 Nocturnus 威胁情报团队称,以色列的受害者。
“这些虚假账户已经运行了几个月,对于毫无戒心的用户来说似乎相对真实,”安全商店的 Nocturnus 机构在今天发布的一份报告中写道。
研究人员发现:“运营商似乎投入了相当大的努力来‘照料’这些档案,通过加入受欢迎的以色列团体、用希伯来语写帖子以及将潜在受害者的朋友添加为朋友来扩大他们的社交网络。”
“随着时间的推移,虚假资料的操作者能够与广泛的以色列公民成为‘朋友’,其中包括一些为敏感组织工作的知名目标,包括国防、执法、紧急服务和其他与政府相关的组织。”
该活动被 Nocturnus 称为“大胡子芭比行动”,是 APT-C-23 的出发点,该活动已在中东运营多年,通常专注于讲阿拉伯语的目标。多年来,该组织在其他活动中使用了相同的相对简单的工具和技术。
然而,对于这项最新的努力,APT 团队似乎已经升级:它现在使用一套新的工具——称为 Barb(ie) Downloader 和 BarbWire Backdoor——具有逃避检测的技术和专注于操作安全性的技术。该小组还在部署改进的 VolatileVenom Android 植入程序。
“此外,所有三个正在使用的恶意软件 [样本] 也是专门设计用于对付以色列目标的,并且没有观察到用于对付其他目标。……这种对目标的‘紧握’证明了这次活动的重要性和敏感性是为威胁行为者准备的,”Nocturnus 说。
APT 团队使用经典的猫钓技术(Facebook 个人资料中有吸引力的女性的假身份)来吸引男性。在获得受害者的信任后,特工建议他们将对话转移到 WhatsApp——并在此过程中获取目标的手机号码——然后经常使用以性为主题的内容来说服受害者使用更加离散的通信方式,例如设计的包含 VolatileVenom 恶意软件的 Android 消息传递应用程序。
他们还引诱受害者在他们的 PC 上打开一个 .rar 文件,其中包含包含色情内容的视频。研究人员写道,一旦他们点击视频,恶意软件就会在后台安装在 Windows 系统上,而目标会被视频分散注意力。
通过 .rar 文件,使用 Barb(ie) 下载器安装 BarbWire 后门。在安装 BarbWire 之前,它还会执行检查以确保没有运行分析工具,也没有类似沙箱的环境。该恶意软件收集有关系统的信息——例如用户名、操作系统版本和正在运行的进程——并将其发送到控制和命令服务器 (C2)。
后门带有许多隐藏自身的技术,从字符串加密到 API 哈希和进程保护,目的是让威胁组织完全控制 PC 并运行键盘记录、屏幕捕获、录音和下载等任务更多恶意软件。它可以搜索包括 PDF、Office 文档、视频和图像文件在内的文件以及包括 CD-ROM 在内的外部媒体。
“搜索这样一种旧媒体格式以及感兴趣的文件扩展名,可能表明关注倾向于使用更多‘物理’格式来传输和保护数据的目标,例如军事、执法和医疗保健,”研究人员写道。
一旦找到,这些数据就会被放入一个 .rar 存档文件中并被泄露到远程命令和控制服务器。Nocturnus 团队表示已检测到 BarbWire 后门的三种变体。
关于 VolatileVenom,APT-C-23 自 2020 年左右以来一直在使用 Android 恶意软件。该活动使用名为“Wink Chat”的虚假消息应用程序作为诱饵;当用户尝试注册使用该软件时,会出现一条错误消息,指出该应用程序将被卸载。同时,恶意软件继续在后台运行,定位和收集数据,然后将其发送到 C2。
“这次活动表明 APT-C-23 的能力有了相当大的提升,隐身性升级,恶意软件更加复杂,以及他们的社会工程技术的完善,其中包括使用非常活跃和精心打造的网络的攻击性 HUMINT [人类智能] 能力已被证明对该群体非常有效的虚假 Facebook 帐户,”研究人员写道。
据路透社报道,援引欧盟数字服务法案 (DSA) 法案,最大的互联网平台将被迫支付每家特定企业全球年收入的 0.1% 以维持其监管机构的费用。
据报道,DSA中提出的规则不会引起欧盟成员国和欧盟立法机构之间的根本分歧,因此该法案很可能会在本月底之前获得当局的同意。
作为欧盟的行政部门,欧盟委员会正在寻找新的收入来源,以在大流行造成的损害中推动该地区经济的增长,并促进向更绿色和更数字化的经济过渡。评估互联网公司的活动,需要一大批专家,预计将由企业自掏腰包提供支持。
据路透社援引该文件的文本称,公司每年向当局支付的款项将取决于对其活动进行监督的估计成本,委员会将根据新规则进行监督。该费用将不超过上一财年最大在线平台全球收入的 0.1%。该费用预计也将与服务规模相称,与欧盟的用户数量保持一致。拥有 4500 万或更多月活跃用户的在线平台将受到法律约束。维基百科等非商业网站除外——它们不会被收费。
欧盟国家代表和欧盟议员拟于4月22日举行会议,参与第四轮讨论,预计各方最终将就与DSA相关的所有问题达成协议。
工作时间:早上9:00-下午6:30
河南快米云网络科技有限公司
 公安备案编号:41010302002363
公安备案编号:41010302002363
Copyright © 2010-2023 All Rights Reserved. 地址:河南自由贸易区开封片区经济开发区宋城路122号