让 HPC 中的 3D V-Cache 时代开始。
研究人员受到AMD “Milan-X” Epyc 7003 处理器及其 3D V-Cache堆叠 L3 高速缓存的想法的启发,然后通过实际基准测试将常规 Milan CPU 与使用真实和合成 HPC 应用程序的 Milan-X 处理器进行对比。在日本的 RIKEN 实验室,基于富士通令人印象深刻的 A64FX 矢量化 Arm 服务器芯片的“Fugaku”超级计算机已经启动了对假设的 A64FX 后续产品的模拟,理论上,该产品可以在 2028 年建造,并提供近一个订单性能比当前的 A64FX 高出很多。
早在 2021 年 6 月, AMD 就让全世界知道它正在为台式机和服务器处理器开发 3D V-Cache ,并展示了一款定制的 Ryzen 5900X 芯片,其芯片顶部具有堆叠的 L3 缓存,仅用一个堆栈就将其容量增加了三倍。(堆叠式 L3 的密度是其两倍,因为它没有芯片上“真正的”L3 缓存所具有的任何控制电路;堆叠式缓存实际上是搭载在芯片上缓存管道和控制器上的。)去年秋天,在 SC21 超级计算大会之前,AMD 公布了 Epyc 7003 CPU 阵容中 Milan-X SKU 的部分特性,而 Milan-X 芯片于今年 3 月亮相
我们认为 3D V-Cache 最终将用于所有处理器,一旦制造技术完善且足够便宜,正是因为这将释放裸片区域以专用于更多计算内核。(我们在接受AMD 高级副总裁兼服务器业务总经理Dan McNamara 采访时讨论了这一点。
RIKEN 的研究人员与东京工业大学和日本国立先进工业科学技术研究所、瑞典皇家理工学院和查尔姆斯理工大学以及印度理工学院的同事合作,得到了他们的手配备 AMD Epyc 7773X (Milan-X) 和 Epyc 7763 (Milan) 处理器的服务器,并运行 MiniFE 有限元代理应用程序——美国 Exascale Computing Project 用于测试 exascale HPC 机器规模的重要代码之一– 在两台机器上显示额外的 L3 缓存有助于将性能提高 3.4 倍。看一看: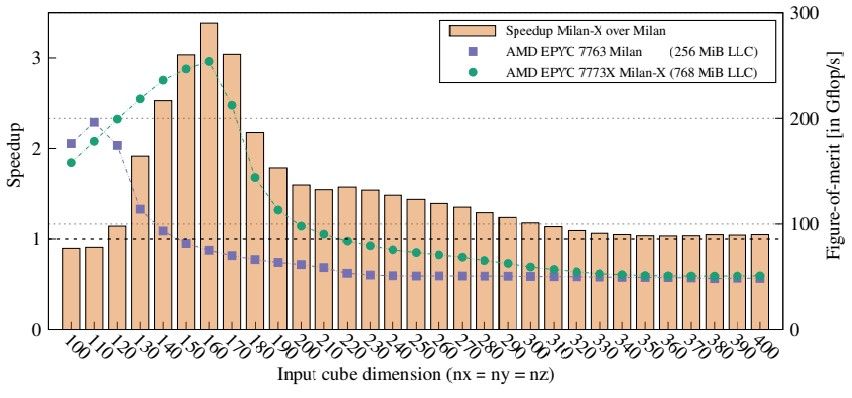
在 HPC 世界中,3.4X 没什么可动摇的。这让 RIKEN 团队开始思考:如果将 3D V-Cache 添加到 A64FX 处理器会发生什么?更具体地说,这让他们开始思考如何将 3D V-Cache 与假设的 A64FX 踢球器结合起来,根据使用 Sparc64 的“K”超级计算机之间的节奏,预计这将在大约六年左右的时间里完成—— 2011 年的VIIIfx 处理器和基于 A64FX 的 Fugaku 超级计算机从 2020 年开始。因此,他们启动了 Gem5 芯片模拟器,并模拟了具有大型 L2 缓存的未来 A64FX kicker(A64FX 没有共享 L3 缓存,但确实有大型共享 L2 缓存),它正在替代 LARC对于大型缓存,可能看起来像以及它在 RIKEN 代码和流行的 HPC 基准上的表现。
这就是创建数字双胞胎的力量,恰如其分地说明。如果你阅读 RIKEN 及其合作者发表的论文,你会发现这项任务并不像 Nvidia 和 Meta Platforms 广告中看起来那么顺利,但它可以做得很好,以获得一阶近似值强制资助未来的研究和开发。
我们对深谷系统中的技术进行了多次深入研究,但最重要的是 2018 年的这一块。这张 A64FX 处理器的照片是开始讨论假设的 A64FX kicker CPU 的好地方:
A64FX 有四个核心内存组,即 CMG,它们具有由富士通 13 核创建的定制 Arm 核心、一大块共享 L2 缓存和一个 HBM2 内存接口。每个组中的一个核心用于管理 I/O。剩下 48 个内核可供用户寻址并进行计算;每个内核都有一个 64 KB 的 L1 数据缓存和一个 64 KB 的 L1 指令缓存,而 CMG 有一个 8 MB 的分段 L2 缓存,每个内核有 32 MB 切片。该设计没有 L3 缓存,这是故意的,因为 L3 缓存经常引起比其价值更多的争用,富士通一直相信在其 Sparc64 CPU 设计中尽可能大的 L2 缓存,而 A64FX 将这一理念发扬光大。L2 缓存在每个 CMG 中的内核中具有 900 GB/秒的带宽,因此 A64FX 处理器的总 L2 缓存带宽为 3.6 TB/秒。
信不信由你,RIKEN 没有 A64FX 处理器的平面图,不得不从 die shot 和其他规格估计它,但它是作为Gem5 模拟器的起点,它是开源的,被很多人使用的科技公司。(如果没有富士通的批准和审查,这个估计是不可能完成的,尽管是非官方的,因此我们认为用于 A64FX 的平面图是绝对准确的。)
一旦有了 A64FX 平面图,RIKEN 团队就假设 1.5 纳米工艺将在 2028 年用于出货处理器。这种显着的缩小使得 LARC 假设芯片中的 CMG 的大小只有所用芯片的四分之一在 A64FX 中,这意味着 LARC 处理器可以有 16 个 CMG。假设 L2 高速缓存可以以类似的速度和规模缩小,LARC 芯片的想法是让八个 L2 高速缓存管芯通过芯片接口 (TCI) 将它们粘合在一起,类似于硅通孔 (TSV) ) 用于 HBM 内存堆栈。RIKEN 认为这种堆叠内存可以在 1 GHz 左右运行,基于对堆叠 SRAM 的模拟和其他研究,从下面的比较 CMG 图可以看出,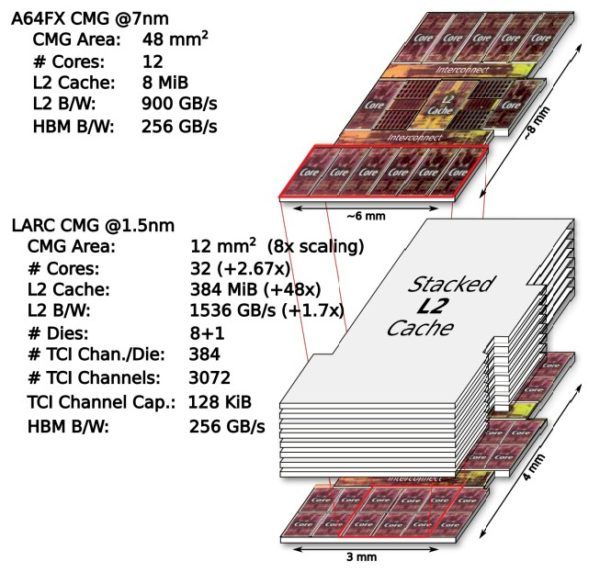
这是一个重要的区别,因为 AMD 的 3D V-Cache 仅将 L3 缓存堆叠在 L3 缓存之上,而不是计算芯片。但我们在这里谈论的是 2028 年,我们必须弄清楚人们会弄清楚在 CPU 内核上安装 L2 缓存的散热问题的材料。以 1 GHz 运行,LARC 的 CMG 中 L2 缓存的带宽将为 1,536 GB/秒,比 A64FX 快 1.7 倍,缓存容量为每个 CMG 384 MB 或 6 GB插座。此外,RIKEN 估计 CMG 将有 32 个内核,是 2.7 倍的倍数。
为了隔离堆叠 L2 缓存对 LARC 设计的影响,RIKEN 将 HBM2 内存保持在 HBM2 级别,并没有模拟 HBM4 的外观,并将 HBM 内存容量保持在 256 GB。我们想知道具有如此高 L2 缓存带宽的 CMG 是否可能不受 HBM2 带宽的限制,而 512 核 LARC 插槽的整体性能可能会受到相对较低的 HBM2 带宽和低容量(仅 8 GB)的抑制每个 CMG)。但是坚持使用 HBM2,每个 CMG 一个控制器,在 LARC 上有 16 个 CMG,即每个 LARC 插槽只有 128 GB 的 HBM2 内存和 4 TB/秒的带宽。假设核心和非核心区域的时钟速度没有太大变化,我们猜想,为了让真正的 LARC 设计保持平衡,可能会提高 4 倍。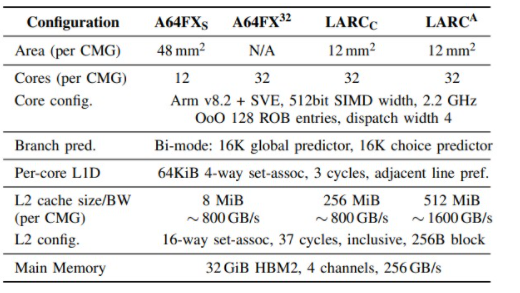
为了隔离内核差异的影响,RIKEN 研究人员设计了一个 32 核 CMG,但每个 CMG 的缓存大小为 8 MB,带宽为 800 GB/秒。只是为了好玩,他们创建了一个 LARC 设计,具有 256 MB 的 L2 缓存和相同的 800 GB/秒带宽(大概只有四个 L2 堆栈)以隔离容量对 HPC 性能的影响,然后在 512 MB 上完成以 1.5 GB/秒的速度运行的 L2 缓存。顺便说一句,LARC 内核中的内核与 A64FX 中使用的自定义 2.2 GHz 内核相同——这里也没有变化。而且你很清楚,到 2028 年,富士通、Arm 和 RIKEN 将拥有更好的内核,但可能没有更好的 512 位向量。(我们将看到。)
以下是假设的 LARC 和实际的 A64FX 芯片在 STREAM Triad 内存带宽基准测试中相互测量的方式: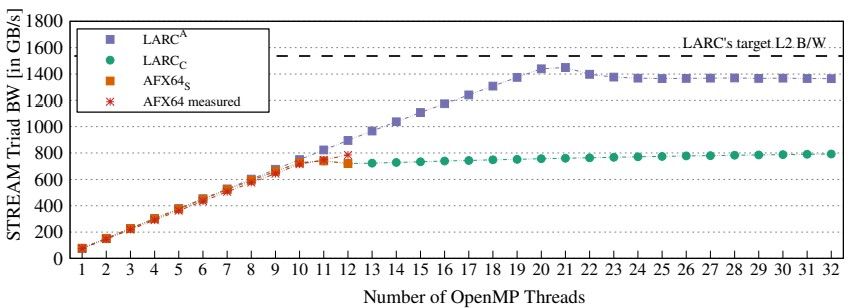
该测试显示带宽随着 OpenMP 线程数量的增加而增加,下面的测试显示了 STREAM 性能如何随着向量输入数据的大小从 2 KB 变为 1 GB 而变化。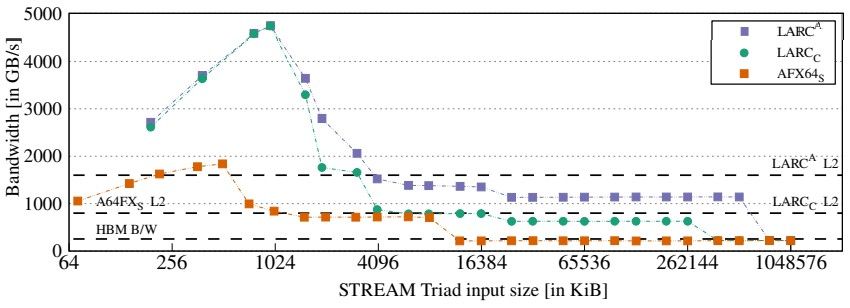
LARC 行的峰值是因为 CMG 中的内核数量是 2.7 倍,而 L1 缓存的数量也是 2.7 倍,因此较小的向量都适合 L1 缓存;然后较大的向量现在可以长时间放入 L2 缓存中。因此,模拟的 LARC 芯片只会启动它,直到所有这些缓存用完为止。
在所有模拟之后,这是重要的事情。在一系列广泛的 HPC 基准测试中,包括在 RIKEN 和其他超级计算机中心运行的实际应用程序以及我们都知道的大量 HPC 基准测试,LARC CMG 平均能够提供大约 2 倍的性能,并且高达 4.5 X 用于某些工作负载。再加上四倍的 CMG,你看到的 CPU 插槽的性能可能会提高 4.9 到 18.6 倍。对于那些对 L2 缓存敏感的应用程序,A64FX 和 LARC 之间的性能改进几何平均值为 9.8 倍。顺便一提:
Gem5 模拟在 CMG 级别运行,因为 Gem5 模拟器无法处理具有 16 个 CMG 的完整 LARC 套接字,并且 RIKEN 不得不对这种规模将如何在套接字中发挥作用做出一些假设。
工作时间:早上9:00-下午6:30
河南快米云网络科技有限公司
 公安备案编号:41010302002363
公安备案编号:41010302002363
Copyright © 2010-2023 All Rights Reserved. 地址:河南自由贸易区开封片区经济开发区宋城路122号