
行业基准很重要,因为无论这种比较是可恶的,IT 组织仍然必须让它们来规划他们未来系统的架构。
由谷歌、百度、哈佛大学、斯坦福大学和加州大学伯克利分校创建的 MLPerf 人工智能基准套件有很多希望,尤其是当谷歌、英特尔和英伟达在 2018 年发布第一个基准测试结果后不久管理 MLPerf 测试的 ML Commons成立。
这个想法是为了让决策者拥有大量数据来决定使用哪些设备进行机器学习、训练和推理,以及从移动设备到边缘机器再到数据中心系统的一切。
但它并没有像标准性能评估公司(SPEC) 的 CPU 级测试、事务处理委员会(TPC)的应用级基准,甚至是 ERP 软件巨头运行的特定测试那样成为无处不在的基准测试SAP 在各种各样的铁上,MLPerf 测试并没有以同样的方式起飞。这通常只是一个检查谁出现了谁没有出现的游戏。许多芯片制造商及其系统合作伙伴并不总是出现,即使出现,他们也不会定期出现,这从 MLPerf 四年前首次推出结果以来就一直困扰着它。
于是这周再次发布了机器学习推理的 MLPerf Inference 2.0 结果,标志着推理结果的第五次发布。(MLCommons 每季度都会发布结果,第一季度和第三季度进行推理,第二季度和第四季度进行培训。)根据 MLCommons 的说法,反应非常强烈,创下了 3,900 多项性能结果的新记录(是前一轮)和 2,200 次功率测量(是之前的六倍),表明人们越来越关注效率。
由于更多的系统制造商参与其中,总体参与度也有所上升。也就是说,英伟达(将人工智能作为平台提供商的发展雄心放在首位和中心)和高通(提交了某些测试的结果)是唯一提交结果的芯片制造商,这一点是首席分析师 Karl Freund Cambrian-AI Research在福布斯专栏中写道,并在 Nvidia 与记者和分析师的演示中询问了该公司的业绩。
在人工智能和机器学习正在成为现代工作负载的驱动力以及制造加速器或人工智能优化处理器的硅供应商数量不断增长之际,亚马逊网络服务、英特尔、谷歌、Graphcore、SambaNova和Cerebras Nvidia 产品营销经理。
Salvatore 强调了行业基准作为一种工具的重要性,它可以为用户提供编号,以便在从性能和能效到成本的各个方面比较竞争产品。然而,事情发生了变化。
“我们在过去几年中看到的一个问题——实际上是自大约十年前开始的深度学习革命开始以来——是结果往往以一种狂野的西部方式发布,”他说过。“它们没有可比性。换句话说,一家公司会声称,“我们提供了如此出色的 ResNet-50 分数”,然后这里的另一家公司会说他们有 ResNet-50 分数,但要么他们没有透露具体如何他们得到了这个数字,或者,如果您阅读脚注,您很快就会意识到每家公司的做法都不同,以至于您可能无法真正比较结果。”
Salvatore 认为,MLPerf 为比较平台提供了一个通用的衡量标准。
“人工智能与我们之前拥有行业标准基准的工作负载没有什么不同,”他说。“您需要这些类型的基准来采用通用的测量方式,以便可以直接比较结果,以便客户可以做出数据驱动的购买决策。最终,行业标准基准所扮演的角色是创建通用标准。”
更多的是进入这个行业。老牌基准测试组织 SPEC 上个月成立了 SPEC ML 委员会,为 AI 和机器学习推理和训练制定基准测试标准。
目前尚不清楚新的基准是否会吸引更多的芯片制造商参与,但有一些方法可以改进现在正在做的事情。与启动基础设施和运行工作负载以达到基准相关的成本可能令人望而生畏,尤其是在一年这样做四次的情况下。并不是每个供应商的产品发布都在同一个时间表上。英伟达的芯片可能已经准备好进行基准测试,而此时英特尔仍在等待其部分芯片上市。
英伟达的大量存在也是一个因素。到目前为止,该公司提交的结果比其他任何人都多。即使这一次,当英特尔和 AWS 没有参与时,英伟达也为他们提交了结果,让其他公司可以利用它的数量。
MLPerf——即使是最新的 MLPerf Inference 2.0——也有功耗数据,并且没有附加到基准产品的价格,有效地消除了大多数企业一直拥有的每瓦性能价格比计算的三个部分中的两个预算有限,在考虑购买什么时使用。
很高兴知道在运行推理工作负载时一个芯片比另一个芯片快多少,但如果无法查看芯片将使用多少功率或它们将占用多少有限预算,那么对于一个组织做出明智的决定。
就结果而言,英伟达在数据中心和边缘表现出了强大的性能。该供应商将其 A100 GPU与英特尔的Xeon “Cooper Lake” 8380H 和“Ice Lake” 8380 服务器 CPU(由 Nvidia 提交)以及高通的 AI 100 机器学习芯片运行,在一系列模型中显示出显着优势,包括用于图像的 ResNet-50分类工作负载,用于自然语言处理的 BERT-Large 和用于医学成像的 3D U-Net。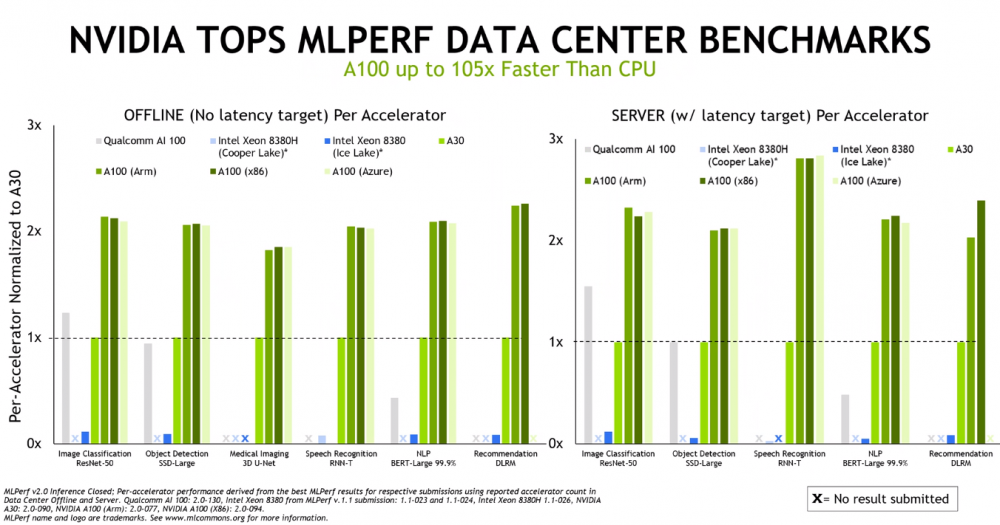
无论是与 x86 芯片、Arm 处理器还是 Microsoft Azure 云实例一起使用,GPU 的性能基本相同。
Nvidia 的 Salvatore 指出,作为其多实例 GPU (MIG) 技术的一部分,供应商可以将单个 A100 GPU 划分为七个实例,并在每个实例中单独运行来自基准测试的工作负载,该芯片可以同时运行所有 MLPerf 测试,对性能的影响约为 2%。他说,这反驳了 A100 只适用于大型网络的论点。
“您还可以使用 MIG 将该 GPU 划分为多个实例,并在每个实例中托管单独的网络,”他说。“这些实例中的每一个都有自己的计算资源、自己的缓存数量和自己的 GPU 内存区域来完成工作。您可以点亮整个部分以达到最佳利用率水平,并能够在单个 GPU 上托管多个网络。对于希望在单个 GPU 上运行多个网络的客户来说,这里有一个很好的效率机会。”
Nvidia 还针对高通公司的芯片测试了 A100 的每瓦性能,再次显示出强劲的效率结果。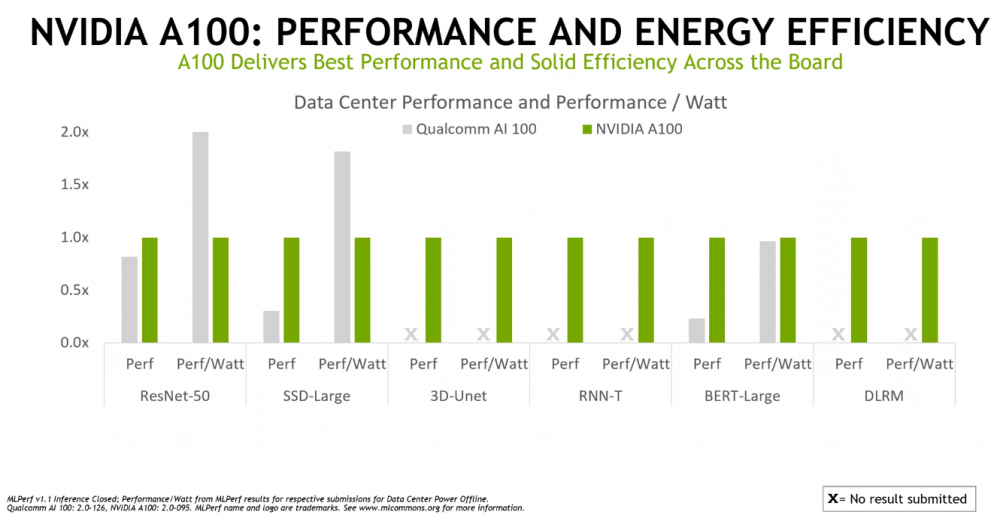
该公司测试了其即将推出的 Jetson AGX Orin 芯片,用于机器人和自动驾驶汽车等工作,其速度是其前身 Xavier 一代的 5 倍,并提供 2.3 倍的功率效率。
除了缺乏对来自各种供应商的每一代架构的测试之外,MLPerf 测试还缺少两个重要的组成部分——功耗和价格。阅读The Next Platform 的每个人都知道,HPC 中心对峰值性能非常感兴趣,但他们必须注意功耗和冷却,并且还知道超大规模生产者受到每瓦价格/性能的推动。等式的所有三个部分都必须存在。MLPerf 测试只说明了该等式的一部分。TPM 威胁要拆散 MLPerf,并将这些价格和功率数据添加到 MLPerf 结果中,并使用一些电子表格巫术作为诱使 ML Commons 从一开始就实际需要这些数据的手段。
工作时间:早上9:00-下午6:30
河南快米云网络科技有限公司
 公安备案编号:41010302002363
公安备案编号:41010302002363
Copyright © 2010-2023 All Rights Reserved. 地址:河南自由贸易区开封片区经济开发区宋城路122号