尊敬的客户:
有菲律宾服务维护提前告知
存储群集升级维护摘要:
维护时间: 2022年1月20日 下午13:00-14:00.
我们在Ma-2云位置对存储集群进行了定期维护。
维护目的:是升级存储群集软件版本。所有计划的任务作业时间50分钟。
所有作业操作均在员工的直接监督下进行。
影响:除了 I/O 操作略有增加外,对正在运行的VM没有影响。
但我们尽一切可能最大限度 减少给客户带来的不便。
感谢您的耐心等待,有任何问题请您及时提交工单或者联系我们。



2021 年春季,NVIDIA 推出了基于 Ampere 架构的新系列 RTX Ax000 和 Ax0 显卡,具有第三代张量核心。我们为 Selectel 服务器选择了最好的。
那时,已经可以 从ZZQIDC租用配备 Tesla M60、T4、V100 GPU 甚至高端 NVIDIA A100 的专用和云服务器。
由于我们只为客户提供采用现代技术的最新硬件,因此我们决定是时候更新显卡系列了。提供 NVIDIA 宣布的所有视频卡对我们和我们的客户来说都是不合理的。最后,我将告诉你我们如何选择最好的,并在测试构建中分享我们的基准测试结果。
我们在ZZQIDC选择硬件(视频卡、处理器和其他组件)的方法非常简单。我们假设客户希望以最低的成本有效地解决他们的业务问题。因此,我们从以下公式开始:
据此,我们在新显卡中选择了领导者。
我们比较了九种 GPU:从 A2000 到 A6000、A10、A16、A30、A40 和 A100 PCIe 的 RTX 显卡。A2000 仅在今年夏天发布,但这并没有阻止我们审查芯片的规格和测试样品。
所有测试参与者都是服务器显卡,桌面 GeForce RTX 3080 和 3090 不在列表中。这些卡(准确地说是安装 NVIDIA 驱动程序)禁止在数据中心的服务器中使用。制造商严格监控对限制的遵守情况:违规制裁不仅适用于供应商,还适用于租用带有桌面硬件的服务器或在其上安装 NVIDIA 软件的客户。
为了评估显卡,我们从对解决客户经常遇到的问题很重要的几个特征开始。也就是说,我们查看了这些 GPU 的一般用途。核心的用途以简化的形式呈现,每种类型都会影响显卡的性能。
其中:
对于 RTX Ax000 系列,性能几乎随型号指数的增长呈线性增长。
A16是四显卡合一。NVIDIA 将该设备定位为专用的 VDI 解决方案。
乍一看,A30 的生产力不如 A10,但 HBM2 内存类型的带宽更大。NVIDIA 将 A30 定位为 AI 解决方案。对于这两种设备,该公司没有公布张量和其他核心数量的数据(从第三方来源获得的特征)。
对比表中其他显卡,顶级PCIe A100方案显存带宽最大,张量核数最大,在意料之中。显然,这个 GPU 的主要目的是处理人工智能和复杂的计算。这是迄今为止 NVIDIA 产品线中性能最高的显卡,尤其是 SXM 外形尺寸的 80GB 版本。但后者是焊接在板上的,出于统一的原因,我们只考虑了 PCIe 外形尺寸中的选项。

按照已经明确的组件选择公式,考虑价格。在2021年很难写到它们,因为芯片危机和持续的供应中断而被人们铭记。
由于两个原因,将没有确切的数字。首先,它是商业机密。其次,也是最重要的,自从这些卡在春季发布以来,价格已经发生了变化(我相信它们将来会继续变化)。
我们将使用这种方法:我们将以 GPU A5000 为标准——它在比较表中的价格将等于 1 只“鹦鹉”。我将通过与 A5000 价格的比率来介绍其余卡的价格。A10 和 A16 的价格范围很接近,因此它们的“成本”相同。
在这个阶段,价格和申报特性的比率是可以预期的。第一个被添加到 Selectel 视频卡系列中作为初级模型角色的候选者是 A2000。同样令人感兴趣的是 A5000、A10 和 A16 之间的平价。
让我们继续测试申请人的表现。
进行设备测试是 Selectel 的常见做法。我们在各种公司产品中使用了大量的硬件,因此我们测试了它们之间的兼容性和软件的兼容性,以及性能。
为此,我们拥有自己的“实验室” 我们甚至提供一些设备给客户在他们的项目中免费测试。从最近的例子来看:我们正在测试一个真正的怪物,它有 8 个同名显卡
为了测试新显卡,我们组装了测试服务器,配备两个来自英特尔的强大处理器和足够的 RAM。
特点如下:
我们选择的基准:
GeekBench 5 是模拟任务执行并确定 GPU 性能的通用基准。
AI-benchmark 是一项性能测试,用于衡量学习速度并将各种神经网络应用于识别和分类任务。
V-Ray Benchmark 是一项检查渲染速度的测试。
ffmpeg NVENC - 视频转码的性能测试。
测试结果列于表中。我们为每个项目确定了领导者。
在撰写本文时,我们手头没有 A16 和 RTX A6000 显卡,因此它们不包含在表中。他们的基准是稍后计划的。
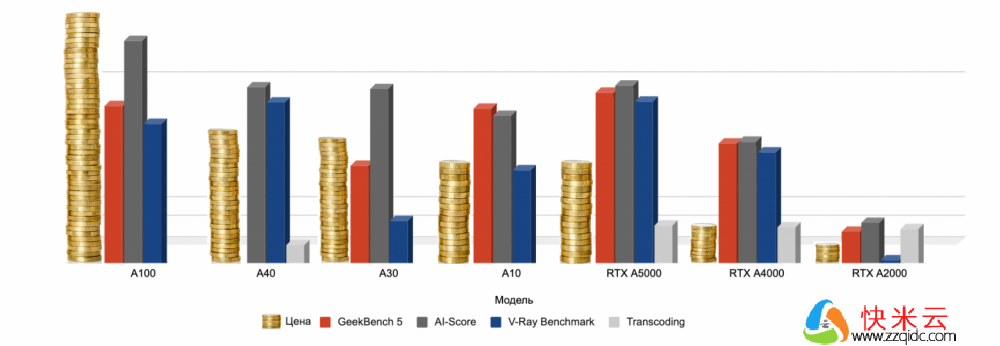
从测试结果来看,A5000在性价比方面胜出。OpenCL Compute Score 中的最佳结果略逊于 CUDA Compute Score 中更昂贵的 A40 和 A100,适用于处理图形。在 A100 之后的 AI 基准测试中排名第二。V-Ray渲染速度测试领先,转码测试领先。支持 VDI。如果与价格表相比,我们无条件地选择。
A2000 比 A5000 便宜五倍,同时显示基本模型可接受的基准测试结果。不支持 VDI,但适用于图形和 AI 任务。
A4000 在性能方面介于 A2000 和 A5000 之间,不支持 VDI,但在价格和基准测试结果方面经受住了批评。
正如我已经写过的,A100 在人工智能、模型训练、推理、数据分析和复杂计算方面是无可争议的领导者。远程桌面基础架构的理想选择。
在比较基准和价格时,其余的 GPU 显示的结果较少。

每年,Gartner都会确定对业务很重要的技术趋势。今年Gartner 概述了2022年的12个战略趋势,这些趋势将帮助CEO为其业务带来效率、数字化和增长,并帮助CIO和IT专业人员在其组织中寻找战略合作伙伴。
Gartner副总裁分析师David Groombridge表示:“CEO 知道他们必须加快数字业务的采用,并找到更直接的数字方法来与客户建立联系。” 但考虑到未来的经济风险,他们也希望企业能够高效运营并保护他们的利润和现金流。”
以下是2022年的12个战略技术趋势——它们为什么有价值?
Data Fabric 提供跨平台和业务用户的数据源之间的灵活集成,使数据无论在哪里都可以在任何需要的地方使用。
Data Fabric 可以分析以了解并推荐数据的存储位置。这可将数据管理工作减少多达 70%。
Cybersecurity Mesh 是一种灵活的架构,可以组合和集成不同或广泛分布的安全服务。
Cybersecurity Mesh 允许独立的安全解决方案协同工作以提高整体安全性,同时将控制点移近它们旨在保护的数据。Cybersecurity Mesh 可以跨云和非云环境快速可靠地验证身份、上下文和策略合规性。
隐私——增强计算确保在不受信任的环境中处理个人数据。随着隐私和数据保护法的发展以及用户对隐私的关注度越来越高,确保隐私变得越来越重要。
隐私 – 增强计算使用各种隐私保护技术来允许从数据中提取价值,同时满足合规性要求。
云原生平台是一种技术,可让您构建弹性、弹性和敏捷的新应用程序架构,帮助您快速响应数字化变化。
云原生平台采用提升和转移方法(一种特殊技术,用于将应用程序、软件或系统从一个环境移动到另一个环境而不显着改变底层设计)进行创新。应用程序、软件或系统的版本)传统对于云,这种方法无法利用云的优势并增加了维护的复杂性。
可组合应用程序是由模块化的功能组件构建的。
可组合应用程序使代码更易于使用和重用,加快新软件解决方案的上市时间,并增加业务价值。
决策智能是一种改进组织决策的实用方法。它将每个决策建模为一组过程,使用人工智能和分析来通知、学习和改进决策。
决策智能可以支持和增强人类决策,并可能通过使用增强分析、模拟和人工智能实现自动化。
超自动化是一种规范的、面向业务的方法,用于快速定义、测试和自动化尽可能多的业务和 IT 流程。
超自动化支持可扩展性、远程操作和业务模型中断。
AI 工程自动更新数据、模型和应用程序以简化 AI 交付。
结合强大的人工智能治理,人工智能工程将推动人工智能交付,以确保其持续的商业价值。
分布式企业反映了数字优先、远程优先的商业模式,以改善员工体验、数字化消费者和合作伙伴接触点并构建产品体验。
分布式企业更好地满足员工和消费者的需求,推动了对虚拟服务和混合工作场所的需求。
全面体验是一种业务战略,它跨多个接触点整合员工体验、客户体验、用户体验和多点触控体验,以加速增长。
通过对利益相关者体验的全面管理,全面体验可以增强客户和员工的信心、满意度、忠诚度和支持。
自主系统是自我管理、从环境中学习并实时动态修改自己的算法以优化其在生态系统中的行为的物理系统或软件。
自主系统创建了一组技术,能够支持新的需求和场景、优化性能并在没有人工干预的情况下防止攻击。
Generative AI 从数据中学习外来元素,并创建一个与原始相似但更具创新性且不重复的新版本。
生成式人工智能有潜力创造新形式的创意内容,例如视频,并加速从医学到产品创造等领域的研发周期。
顶级技术趋势将通过解决 CIO 的业务挑战来推动数字化转型并推动增长。它们提供了一个路线图,以发挥作用、实现业务目标并为组织寻找战略合作伙伴。
每个技术趋势都会产生以下三个主要结果之一:
通过确保在云和非云环境中更安全地集成和处理数据,创建灵活高效的 IT 平台,优化 IT 平台扩展成本。
通过发布新技术解决方案来扩展和加速数字化。这些技术趋势允许通过创建自动化业务运营、优化人工智能 (AI) 和更快地做出更明智的决策来响应数字化的速度。
通过利用新技术趋势获得业务市场份额。同样的趋势推动增长,使您能够创造最大价值并提升您的数字能力。
不同的技术趋势将对其他组织产生不同的影响。趋势的紧密结合可以满足业务增长周期中的许多需求。技术趋势的选择将由CEO、CIO 决定,以匹配组织的长期和短期业务目标。

为您的服务器选择合适的操作系统是高效流畅运行的关键。服务器操作系统直接影响存储系统的便捷性、安全性以及快速扩展存储系统的能力。在本文中,我们将讨论用于处理和存储数据的最流行的操作系统。它将主要对那些开始熟悉托管和托管 Web 项目的功能的人有用。
让我们澄清一个重要的点:服务器的操作系统,尽管种类繁多,但属于 Linux 或 Windows 家族之一。如果您面临选择服务器操作系统的任务,我们将概述有助于您比较选项并选择最佳选项的主要标准:
最后,服务器操作系统的选择直接取决于使用目的。例如,单页网站和大型在线商店需要完全不同的选项。请注意,无论选择何种操作系统,在虚拟服务器上运行的服务都将同样可供客户端使用。您的客户不会知道您的项目使用的是哪个操作系统。唯一的区别在于处理数据的环境。只有维护虚拟服务器的 IT 专家才能看到它。
服务器基于特定的操作系统。我应该为服务器选择哪种操作系统?要做出决定,您需要比较几种流行的解决方案并考虑它们最重要的功能。
这可能是最实用的文件存储解决方案。但是您不应该将 Windows Server 与安装在个人计算机上的大多数操作系统进行比较。该系统是通用的,用于应用程序、文件和邮件服务器。但是,使用 Windows Server 时可能存在安全问题。事实上,大多数病毒都是为 Microsoft 软件编写的,这可能会降低管理期间的保护级别。但请注意,最新版本的系统对恶意软件的抵抗力更高。此外,高质量的防病毒软件将提供救援。
FreeBSD 是一个相当古老但仍然有效的文件服务器操作系统。它的第一个版本于 1993 年发布。它是可靠的软件,可以防止病毒和黑客攻击。而且 FreeBSD 还可以在多个应用程序同时运行的情况下进行良好的调试资源节省。它还支持广泛的硬件。FreeBSD 的最大优势之一是定制灵活性。
它的缺点包括安装某些设备的复杂性、缺乏文档、需要使用命令行的技能。FreeBSD 没有单独的图形界面。这些设置在适当的配置文件中进行。因此,一个没有特殊技能的人将很难应付。
这是一个 Linux 发行版,其特点是其多功能性,可用于服务器操作系统和个人计算机。Debian 确保稳定流畅的运行。因此,许多人认为它是服务器的最佳操作系统。可以认为只有一个缺点 - 很少发布更新。
回答关于服务器选择哪个操作系统的问题,让我们谈谈红帽企业 Linux。它非常适合企业应用程序并且很受欢迎。这个操作系统的优势无疑是它的高水平。红帽企业 Linux 仅收费提供。更新版本每 3 年发布一次。
如果服务器不受持续高负载的影响,可以使用具有简单管理的免费选项。如果您选择的服务器操作系统是 Ubuntu,我们注意到这也是一个极好的安全级别。现在它是服务器上最常见的系统之一,适合部署甚至相当大的项目。
服务器需要什么操作系统?让我们多谈谈免费运行的 CentOS。其主要优点:
缺点是所需软件的更新很少。
选择哪个主机:Windows 还是 Linux?这些操作系统组彼此不同,这在选择合适的解决方案中起着基础性作用。
对于任何操作系统来说,这是最重要的组件,因此在安装最佳服务器的问题上,它可以说是决定性的。
Linux内核是:
Windows 内核存在显着差异。它的特点是以下参数:
Windows 内核具有很强的适应性。此外,新版本的 WinServ 也非常适合在多线程模式下工作。
谈到 Linux,我们注意到该操作系统提供以下功能:
Windows中文件放置的特点:
如果我们根据文件系统和磁盘的特性来考虑为 VPS 选择哪种操作系统,我们注意到 Windows 的使用频率要低得多,因为此类服务器的价格很高,因为需要购买操作系统的许可证。因此,就质量和价格比而言,最好的选择是 Ubuntu Server。
在存储设置时,不仅用户的舒适度很重要,安全性能也很重要。Linux 设置存储在标准文件中并适用于所有用户。如果我们谈论软件设置,它们位于隐藏的子目录中。
现在让我们来看看 Windows 设置是如何存储的:
这两个选项都非常安全,但 Windows 有一个明显的缺点——无法传输。
使用 Linux 可提供高级别的安全性和不间断的更新。对于 Windows,该操作系统具有以下特点:
总结:没有明确的领导者。一些用户被直观的 Windows 界面所吸引,而另一些用户则被具有高安全标准的 Linux 所吸引。
在决定为 vps 选择哪种操作系统时,建议考虑项目的规模、站点的具体情况和托管类型。您可以从我们公司租用专用的 Windows 服务器或订购虚拟 VPS Linux 服务器进行租用。让我们列出每个租用专用服务器的客户保证的主要优势:
从快米云租用虚拟服务器是:
您有问题或需要帮助吗?您可以通过网站上的聊天联系我们。我们诚邀您的合作,这将有助于您现在的事业繁荣!
计算系统经常面临繁重的工作负载,这也适用于云技术。为了优化性能并满足用户需求,系统正在扩展。应用创新的软件资源来根据客户需求调整性能。缩放被认为是最有效的技术。
在本文中,我们将定义什么是云可扩展性并描述技术类型。
服务器可扩展性是一种通过添加计算资源来提高系统性能的方法。这适用于硬件和软件修改。为此,重写了现有代码。
一些公司认为,如果云服务器的整体性能指标对工作流变得无效,则应该采用扩展。但即使运行稳定,也可能由于用户流量的增加而周期性地出现问题。
可以使用特殊的测试工具检查过载电阻。用户流向服务器的增加是人为造成的。启动应用程序后,您需要评估 2 个指标:
显示 RPS – 每秒的请求数,据此估计服务器系统故障的概率。
云可扩展性选项
当无法更改服务器的配置和优化时,扩展云资源是最好的解决方案。完成:
如何创造最大的可扩展性?您可以使用集群来提高系统性能,这是一种非常节省资源的方法。该技术旨在将服务器分发和组合到容器和集群中。还要注意缓存。由于水平扩展无法执行多个组件的简单缓存,因此使用高度安全的存储执行优化。
那么,云中的服务器可扩展性究竟是什么?这是提高系统性能的最佳方式。通过添加计算资源(软件和硬件)来实现。
您可以在其中为不同复杂性的项目选择必要的服务器,包括在服务器扩展方面获得专业帮助。在租用云服务器是一个显着提高整个公司绩效指标的机会。在该站点上,您可以查看所有 vps 服务器的资费。

在加入IDC之前,我曾在一家产品和流程创新咨询公司工作。技术人员——我的许多同事——由一百多名拥有多个博士和博士后学位的机械、电气、化学和其他工程师组成。该公司还积极维护着一个科学家网络,他们扮演着咨询角色,可以随时咨询。在我的十年任期内,这个网络增长到了数千个。该公司的主要客户包括财富 1000 强公司——主要是制造业和消费品行业——拥有大量研发投资。
按照大多数标准,这家咨询公司相对较小——主要是大型咨询公司的同行群体——但这并没有阻止它代表客户承担一些非常酷的任务。它为电信行业设计了微型天线(几毫米高),解决了铝制卡车车轮制造的棘手生产问题,解决了天然气管道的腐蚀问题,降低了太阳能电池板的成本,开发了油漆涂层的新方法,甚至推出突破性的牙齿美白解决方案。
这家公司怎么能在这么多不同的学科中如此有效?因为一种促进创新的文化。该公司开发了一种系统的创新方法,可以应用于任何工程、科学或研究领域。这种方法将“工程系统”,无论是牙齿美白系统还是卡车车轮制造系统,解构为其底层组件之间的功能。它确定了哪些功能是有用的,哪些是不必要的,甚至是有害的,然后通过消除不必要或有害的功能,增加有用的功能来重建系统。对于那些知道的人,这种方法是基于 TRIZ -创造性解决问题的理论. 各种其他的分析工具也被应用了,这里我就不深入了。
有人可能会争辩说,这家公司构建了需要优化、原型化或操作化的工程系统的“功能双胞胎”。这早在“数字双胞胎”(在运营技术的背景下使用)之类的术语变得司空见惯之前(“数字双胞胎”是物理对象或过程的虚拟表示和实时数字对应物)。事实上,除了基本的笔记本电脑外,没有计算机参与这家公司的技术人员使用的分析过程。简而言之,这家小型创新咨询公司能够蓬勃发展的真正原因是,它的大客户中很少有人投资或可以访问大型高性能计算 (HPC) 系统(例如可以在研究中找到的系统)当时的机构和大学),别管它有内部技能,可以将相关问题编码或编程到这些 HPC 集群上。可以说,这家咨询公司的 100 名工程师的核心员工和 3,000 名科学家的附属员工代表了并行的人机,有点像 NASA 用于早期阿波罗任务的“人机”,除了几十年后。
今天,公司不能再依赖“人机”进行研发活动。激烈的竞争、对保持或促进组织差异化的不断追求,以及在数字信息中做出决策的需要,意味着几乎每家公司——无论行业如何——都必须投资于高性能计算、人工智能和分析基础设施。他们必须聘请能够有效利用这些系统的技术人员。我们正处于英伟达首席执行官黄仁勋所说的“HPC 工业化”时代。如果数据是新的石油,HPC 的产业化旨在确保原油能够在内部和外部快速提取、精炼并适合消费。我工作的公司作为服务提供给有能力的客户,
彻底改变商业投资和成果
HPC 的工业化——有时也被称为 HPC 的民主化——只不过是 HPC 技术变得司空见惯。它们的采用不再局限于资金充足的国家实验室和大型大学。HPC 正在公共和私人研究机构、云计算、数字和通信服务提供商中获得更广泛的采用,而且——至关重要的是——在许多企业中。这正在彻底改变商业投资和成果:
无论是本地 HPC 系统的资本支出还是 HPC 即服务的运营支出,以可管理的成本(和可衡量的回报)不断增长的海量计算的可用性,都为科学家、工程师和技术人员提供了巨大的支持能力。再加上丰富的数据集,对海量计算能力的访问为科学家带来了一种新的研发文化。在没有惩罚的情况下增加迭代运行的能力允许他们在可接受的时间范围内尽可能频繁地调整模型或运行模拟。
最后一点不仅仅是启用多次运行。它还允许企业的研发在其领域采用一种基本的科学和数据主导的方法,在这种方法中,他们不仅试图开发解决方案,而且还开始积极寻找新问题(可以使用算法方法解决) )。颠覆性创新在于利用技术寻找新问题,而这通常是科学发现的起点。
IDC 的高性能计算
所有这一切让我明白为什么这是 IDC 的一个重要领域,以及为什么我有幸领导 IDC 在该领域的再投资。IDC 的客户(包括供应商、服务提供商、最终用户和金融投资者)继续寻求有关高性能计算的高质量市场研究和情报。一段时间以来,他们一直在呼吁 IDC 扩展其全球研究框架,将 HPC 包括在内。我在这里告诉你,我们清楚地听到了你的声音。换句话说,IDC 对 HPC 的报道源于市场对可靠和可操作的市场数据和洞察力、相关趋势的未满足需求,以及 HPC 与人工智能、量子计算和加速计算等新兴领域的关键融合。在这样做,我们希望确保任何新的 HPC 相关覆盖在分类和本体上都与 IDC 的全球行业研究框架保持一致。这是IDC的战略投资领域,我们将全力以赴。
从2022年1月开始,IDC 将启动两个以 HPC 为重点的联合研究计划(称为持续情报服务或 CIS)。这些项目(这将是我实践的一部分,我正在为此聘请两名分析师——更多内容见下文)将从各个方面跟踪 HPC 市场和行业,包括在国家实验室、大学、企业和其他组织完成的工作在全球范围内。这两个程序是:
这两个计划都将为供应商和服务提供商提供智能,因为他们寻求提供技术堆栈即服务,以实现与高性能计算相关的各种用例
IDC 多年来一直密切关注 HPC 市场,使用“建模与仿真 (M&S)”一词。我们将 M&S 作为一个用例组进行了检查,该用例组分布在我们的企业工作负载细分市场中,并与我们跟踪的企业基础设施市场相关联。此外,我们定义、跟踪、规模、预测和细分相邻市场、技术和用例组,即:
在此过程中,我们得出结论,上述所有内容都可以归为一个总称:性能密集型计算 (PIC),特别是因为用于部署与这些用例组相关的工作负载的计算和存储基础架构的融合。
IDC 将性能密集型计算 (PIC)定义为执行大规模数学密集型计算的过程,通常用于人工智能 (AI)、建模和仿真 (M&S) 以及大数据和分析 (BDA)。PIC 还用于处理大量数据或以尽可能最快的方式执行复杂的指令集。PIC 不一定规定特定的计算和数据管理架构,也没有规定计算方法。然而,某些类型的方法,例如加速计算和大规模并行计算,自然而然地获得了突出地位。
从性能密集型计算的背景来看,IDC 认为 HPC 由三个主要细分市场组成:
当我们定义这些市场时,我们会确保它们无缝地结合在一起——就像一个谜题。我们还确保它们在逻辑上符合 IDC 对全球企业基础架构市场的定义和跟踪方法。下图显示了在 IDC 的分类中,这些市场如何组合在一起。
十年前,像我在加入 IDC 之前工作的那家公司使用人类专家通过创建工程系统的功能双胞胎来开发解决或优化问题的方法。工程师将花费数周时间将系统拆开(在纸上),定义所有组件之间的功能,删除有害或不必要的功能,添加有益的功能,然后用创新的新功能重建系统。如今,工程系统以数字方式重新创建、分析和优化,产品和流程创新在 AI、HPC 和 BDA 的支持下进行,科学家必须具备软件开发专业知识。这种转变不亚于各种规模公司的研发和工程部门的全球数字化转型。

裸机云服务器是一种单租户、非虚拟化机器,它为用户提供对底层硬件的完全访问权限,而无需任何开销。它保留了云的完整、自助服务的多功能性,同时允许用户利用服务器物理硬件的全部处理能力。本文将解释什么是裸机云,它是如何工作的,以及它相对于虚拟化云解决方案的优势。
通常,虚拟化云环境会因管理程序而导致性能下降。管理程序是运行云的技术。管理程序使用额外的资源,从而产生额外的开销,对处理器密集型操作产生负面影响。解决这些问题但仍保留类似云的灵活性的需要导致了裸机云的发展。
与公共云不同,裸机云服务器不依赖管理程序在服务器上创建单独的虚拟机。裸机云完全依赖物理服务器来提供最高性能,而无需虚拟化开销。
管理程序层提供了在单个服务器上运行多个虚拟机并产生额外处理开销所需的可见性、灵活性和管理功能。裸机服务器通过将操作系统直接安装到磁盘上来消除对层的需求。这也允许配置其处理器、存储和内存,这些在虚拟化案例中不共享。
虽然虚拟化云基础架构在多个共享硬件中运行并托管多个租户,但裸机服务器仅托管一个。换句话说,裸机云服务器完全专用于一个客户,而不是在客户之间共享。
裸机云是基础架构即服务 (IaaS) 云服务的子集。在 IaaS 模型中,用户可以从服务提供商处租用物理服务器。裸机云包含专用服务器硬件以及数据中心网络、存储和托管它的设施。
因此,裸机云模型与超大规模企业中常见的标准虚拟化云模型相比具有几个优势。让我们深入研究裸机云提供的好处。

裸机云和虚拟化云模型都提供类似的功能和优势。它们都有助于基于需求和基于 DevOps 的配置和按需付费预算。但是,裸机云还有一些额外的好处,包括硬件控制、可扩展性和性能优化。
如前所述,引入管理程序层通常会导致性能下降。裸机云通过使用专用服务器环境补充或替换虚拟化云服务提供了一种解决方案,该环境在不牺牲灵活性、可扩展性和效率的情况下消除了开销。
可定制性。裸机云的一个显着优势是它是高度可定制的。它允许NVMe 存储用于每秒高输入/输出操作、特定 GPU 型号或自定义 RAM 与 CPU 比率或 RAID 级别。可以根据客户的规格构建物理裸机服务器,让他们受益于定制硬件的额外性能。虽然,可定制性是有代价的。与虚拟化云相比,可定制性限制了扩展资源的能力。
专用资源。对于要求高数据吞吐量水平的应用程序,虚拟化云环境固有的多租户设计往往受到限制,导致多租户虚拟化公共云平台相互竞争。因此,它们限制了数据密集型工作负载的 I/O,并导致低效和不一致的性能。
另一方面,裸机服务器支持高性能计算。它们没有被虚拟化,也没有运行会产生额外开销的管理程序,但仍然可以在基于云的服务模型上运行。
所有服务器资源都专用于一个用户,因此用户不必与其他租户共享资源。借助裸机云,用户可以直接访问具有全部功能的专用硬件。
硬件控制。裸机服务器允许完全控制服务器硬件。硬件是完全专用的,包括任何额外的存储。裸机云相对于虚拟化云环境的优势使用户能够完全控制物理处理器、内存和存储资源。
通过利用管理员级别的权限,用户可以对服务器的进程进行微观管理、优化性能并安装其他应用程序。它们可以通过 API 或基于 Web 的门户按需配置和取消配置。
高效的计算资源。在 CPU 处理能力、内存和存储方面,裸机服务器提供的计算资源比虚拟化云服务器更具成本效益。此外,根据使用案例,单个裸机云服务器可以处理比类似大小的虚拟化服务器更大的工作负载。
可扩展性。裸机云允许用户通过添加额外的存储、处理能力和内存来扩展他们的资源,以确保在最需要时提供最大可用性,并在不再需要时将其删除。但是,与虚拟化云环境相反,扩展裸机云资源需要服务提供商添加和删除硬件,这需要物理时间。

组织对灵活性和效率的不断增长的要求使他们以前涌向公共云基础设施服务,现在又涌向裸机云。它提供了削减成本的机会和技术创新的资本化。
许多公司正在通过减少管理开销和提高运行速度来转向裸机服务器。
公共云可以处理许多工作负载,例如简单的 Web 应用程序甚至大型数据库。但是,与仅裸机云服务器所能提供的相比,专门的工作负载需要更多的功能和敏捷性。
当客户需要在没有延迟或开销延迟的情况下执行短期、数据密集型操作时,高性能裸机云功能最适合。这些操作包括大数据应用程序、分析、媒体编码、渲染、网格计算和其他需要一致性能的工作负载。让我们仔细看看一些裸机云用例。

构建应用程序。裸机云让开发人员可以更方便地构建、测试和部署应用程序。根服务器访问和原生云架构使他们能够利用容器化和编排软件解决方案将基础设施视为代码。
此外,裸机云通常用于计算资源使用稳定且不间断的情况。当应用程序不依赖 PaaS 服务时,硬件占用空间相当大,并且必须考虑成本。
数据库工作负载。当公司需要分析大量数据时,虚拟化环境在性能方面无法与裸机云相提并论。裸机服务器是大数据工作负载的理想选择。它允许按需灵活地定制、配置和管理物理机器。
当使用特定硬件组件或集成高性能 NVMe 磁盘时,通常会使用裸机云。NVMe 存储允许用户在不影响性能的情况下运行要求苛刻的应用程序。它在分析物联网数据时提供速度和可扩展性。在裸机云环境中,所有资源都专用于运行分析应用程序,没有虚拟化开销。
游戏服务器。裸机服务器非常适合需要原始计算或 3D 渲染性能的游戏应用程序。由于游戏服务器需要尽可能低的延迟和最大的 I/O 吞吐量,裸机服务器及其专用硬件可以提供最佳性能。裸机云不仅消除了延迟,而且凭借裸机硬件的速度以及可扩展性和成本效益,满足了当今游戏行业的高性能需求。
渲染农场。由于 3D 渲染是一项处理器密集型操作,因此使用裸机云可显着减少渲染时间。虽然许多 3D 动画公司仍然使用现场专用服务器来实现性能一致性,但裸机云环境通过允许管理员访问服务器来提供硬件定制和性能优化。
边缘计算。由于边缘计算将处理能力转移到网络边缘,更靠近数据源,边缘计算和裸机云服务器使公司能够在访问数据的速度方面获得优势。在裸机服务器上运行的容器受益于更低的延迟,这比在虚拟机上运行的时间低大约三倍。
虽然裸机云的使用不仅限于上述行业,它还用于广告技术和金融科技应用程序、视频流应用程序等,但裸机服务器通常用于高性能计算,任何开销都应该是避免,并且硬件组件必须针对性能进行定制。
凭借裸机服务器提供的所有潜在优势,使用专用服务器存在一些风险。有缺陷的 CPU、SSD 或内存条可能会使服务器崩溃。另一方面,虚拟化云服务器可以处理组件故障并保持客户端服务器正常运行。因此,为了避免硬件故障导致的灾难性后果,需要裸机云具有服务器冗余。
与虚拟化云产品相比,裸机云提供了许多优势。但是,鉴于裸机云必须提供的所有好处,希望购买此服务的组织应该拥有能够在裸机云环境中工作的经验丰富的团队,或者可以在需要时提供支持的优质服务提供商。
公司必须经历过 DevOps 并具备使用裸机技术的知识,才能从其优势中受益。不知道如何设置应用程序以从裸机服务器中获益的管理员和开发人员可能会发现整体性能没有差异。
拥有可靠的裸机服务提供商可以帮助您避免设置应用程序和优化性能方面的所有挑战。使用ZZQIDC裸机云产品部署您的数字基础架构可确保您不仅获得卓越的性能、安全性和可扩展性,还可以获得我们团队的全天候专家支持。

大型 IT 公司拥有昂贵的“玩具”,大多数用户看不到它们。今天,我们将揭开神秘面纱,向您介绍一个针对人工智能进行优化的系统。
AI任务对计算和网络资源的要求很高,所以我们今天的“客人”会用它的配置来取悦你。认识 NVIDIA DGX A100。
NVIDIA DGX A100 是一款 6U 机架式服务器,重量超过 130 公斤。服务器,即使在一个盒子里,也能陷入轻微的刺激之中。硕大的身躯和美丽的金色吸引了路过同事的目光。
服务器在一位工程师的陪同下到达,他为我们提供了身体和精神上的支持。当我们的员工打开包装并准备将服务器运送到安装地点的工具时,工程师讲述了有关该服务器的有趣事实。因此,安全预防措施规定使用机架式电梯,并且至少需要两个人来拆卸服务器。
服务器机箱没有从顶部打开。相反,服务器背面有两个托盘 - 这些是服务器的组成部分,包含服务器的“填充物”。请注意,机箱中的托盘固定螺钉为绿色,而托盘盖固定螺钉为黑色。
六个 3 kW 的热插拔电源吸引您的眼球。有趣的是,声明的最大功耗为 6.5 kW。答案很简单:电源按照3+3方案运行,即2N冗余。最常见的 GPU 机箱提供 4 个电源和一个 3+1 电路。
底部托盘显示 10 个网卡端口,带宽高达 200 Gb/s。缺省情况下,双口卡配置为以太网模式,其他配置为Infiniband模式。这些 NIC 用于将多个 DGX 组合成一个计算集群。我们只有一个 DGX,所以没有使用任何端口。
俄罗斯的超级计算机之一 Christofari 由 75 台 DGX-2 服务器组装而成,该服务器基于上一代图形加速器。
服务器的前面板看起来像是带有 GPU 的服务器:很多大风扇。它们能够达到 18,000 rpm 的转速,让您可以有效地冷却服务器丰富的内部世界。服务器软件本身控制着风扇转速,并不给用户提供干预这个过程的机会。
起初,我们想尝试自己运行 DGX,但不幸的是,我们遇到了一个意想不到的问题。在调试期间,服务器显示与 BMC 的通信错误,并将所有风扇旋转到 18,000 rpm。在随行工程师的帮助下,错误得到修复,服务器开始正常工作。即使在压力测试期间,他也不再达到这样的速度。
前面板用磁性紧固件上的特殊盖封闭。从远处看,前面板上似乎描绘了白噪声,但实际上它是金属,有许多孔可以让空气通过。
在测试过程中,发现这个盖子对散热片的影响并不大,服务器风扇做得很好。
经过外部检查后,服务器被移至实心台上并拆开。
特定的 GPU 托盘连接器 如前所述,服务器由两个托盘组成:CPU 和 GPU。每个托盘都是服务器的一部分,包含在自己的铁盒中,铁盒安装在机箱中。前面板上的托盘、风扇和篮子之间的通信由安装在机箱中的背板提供。从某种意义上说,DGX 是一款经典的刀片机箱,只不过不是单独的服务器(刀片),而是安装了一台服务器的一部分。
GPU 托盘。很多散热片 顶部是一个占用 3U 的 GPU 托盘。即使是两个人也很重。在托盘的顶盖上还有一个关于物体重量和需要两个人一起工作的警告标志。
此托盘包含 8 个 40 GB 修改的 NVIDIA Tesla A100 显卡。它们的特点是 SXM4 外形尺寸。此版本的视频卡以其夹层设计和增加的散热而著称:400 W 与 PCIe 版本的 300 W。
除了八个用于显卡的大型散热器外,托盘上还有六个较小的散热器。这些散热器冷却实现视频卡互连的芯片。NVLINK 和 NVSWITCH 技术以 600 Gb/s 的吞吐量以网状拓扑连接八个视频卡(每个视频卡都连接到每个视频卡)。
CPU 托盘。还有很多散热器。 CPU 托盘有两种提取方法:全部和部分。
在第二种情况下,托盘离开机箱的长度比带有 PCIe 插槽的部件的长度稍长,并被固定,托盘盖打开。这允许您在不移除整个托盘的情况下使用网卡或操作系统驱动器。
从 CPU 托盘的侧面看,它看起来像一个没有电源的普通 2U 服务器。一对 AMD EPYC 7742 处理器隐藏在大型散热器下,共有 128 个物理内核或 256 个逻辑内核。附近有 16 个 DDR4 记忆棒,频率为 3200 MHz,每个容量为 64 GB。RAM 总量为 1 TB。
有趣的是,处理器的散热器一个接一个,也就是说,第二个处理器被第一个处理器的热量冷却。然而,使用 DGX 冷却系统,它看起来微不足道。在这个托盘上也可以看到异常大的散热器。与 GPU 托盘的交互给 PCIe 桥带来了沉重的负担,这也需要冷却。
电子城 插槽之间是一块电子元件密度最大的小板。它看起来像一个小型电子城。这里识别出ASPEED芯片,它是BMC模块的“心脏”。此外,还有受信任的引导模块,可确保平台的安全性。
具有 640 GB 视频内存的 DGX A100 有一个“较旧”的修改。在其中,RAM 量已扩展至 2 TB,并且持久性存储量也有所增加。
我们对 DGX 内部世界的了解到此结束。让我们在工作中看到它。
203×53分辨率不足以在htop中显示所有核心 在 DGX 的盒子里有一个闪存驱动器,在闪存驱动器上有一个准备好的操作系统映像,可以开始使用。该映像基于带有预装驱动程序和特殊实用程序的 Ubuntu 20.04.3 LTS 操作系统。
我们正在启动的服务器已经走过了漫长的道路,在此期间它已经被拆卸和重新组装。在运输和操作之后,值得检查服务器系统的完整性。根据安装规定,DGX首次上线的相关操作必须由一名随行工程师进行,但我们很好奇,所以所有操作都是联合进行的。
一些操作是通过nvsm实用程序执行的,这是一个用于 nvidia 系统管理的控制台界面。只需一个命令即可检查服务器的“理论”状态:
nvsm show health该团队检查它可以“到达”的所有内容,即:
- 所有声明的 PCIe 设备的存在:NVMe、网卡和视频卡;
- 使用 PCIe 4.0 和每个设备的最大可用通道数;
- 显卡的拓扑结构以及每个显卡通过 NVLINK 的所有邻居的可用性;
- 已安装的记忆棒数量及其 P/N;
- 逻辑处理器核心数。
最后,我们得到了关于平台完整运行状况的预期线。
Health Summary -------------- 168 out of 168 checks are healthy 0 out of 168 checks are unhealthy 0 out of 168 checks are unknown 0 out of 168 checks are informational Overall system status is healthy 100.0% [=========================================] Status: healthy监管的下一阶段是启动压力测试。这不仅会检查系统的运行情况,同时还会为我们提供有关各种服务器组件的最大实际功耗和温度的信息。nvsm实用程序也有助于完成这项任务。
nvsm stress-test压力测试非常方便。该实用程序加载处理器、视频卡、RAM 和持久存储,并开始监控系统事件、温度、风扇速度和功耗。20 分钟后,在测试结束时,会显示一个统计表。
System Resource Metrics Component Pre-test Min Avg Max Unit CPU_LOAD 76.65 0.69 87.79 103.12 % CPU_TEMP 46.50 46.50 66.61 68.50 C DISK_LOAD 0.11 0.00 16.44 37.87 % GPU_LOAD 0.00 0.00 84.72 100.00 % GPU_TEMP 33.13 33.13 62.49 67.88 C MEM_LOAD 0.88 0.88 74.11 89.56 % MEM_TEMP 33.75 33.75 36.10 36.75 C FANSPEED 4812.09 4812.09 7269.36 7538.64 RPM POWERDRAW 1586.00 1586.00 4437.73 4745.00 W System stress test successful. No alerts seen.在这里你可以看到处理器和显卡的温度没有超过 69 度,而风扇的工作力还不到一半。功耗为 4.7 kW,比规范中规定的低近 2 千瓦。不过这次压力测试没有考虑到十张外网卡,我们的DGX版本也不是最老的。
现在服务器已经过测试并准备就绪,我想运行测试来看看这台计算机的能力。虽然这台服务器更多是为 AI 任务准备的,但没有人取消进行定期测试的愿望。
我们从 GeekBench 5 Compute 开始。不幸的是,这个基准测试不使用视频卡之间的互连,并且一次只测试一个设备。不过,可以用来比较 SXM4 版本的 Tesla A100 如何优于 PCIe 版本。
类别 PCIe 特斯拉 A100 40G SXM4 特斯拉 A100 40G 开放式 170137 188380 (+11%) CUDA 213899 234890 (+10%) 我们运行的第二个基准是 ai-benchmark,这是一种性能测试,用于衡量学习速度并将各种神经网络应用于识别和分类任务。尽管此测试使用了 Tensorflow GPU,甚至在日志中也注意到显卡之间存在互连,但它仅在一个显卡上运行。因此,此测试仅用于比较不同的 Tesla A100 外形尺寸。
类别 PCIe 特斯拉 A100 40G SXM4 特斯拉 A100 40G 推理分数 25177 30158 (+20%) 训练分数 23775 27837 (+17%) AI Score 48952 57995 (+19%)
结论
NVIDIA DGX A100 是一款功能强大的服务器,旨在加速 AI 工作负载。DGX 有很多复杂的技术细微差别和特性,但在一些常规性能测试中无法感受到它们。要看到这台服务器的真正威力,你需要自己去“触摸”它。。
工作时间:早上9:00-下午6:30
河南快米云网络科技有限公司
 公安备案编号:41010302002363
公安备案编号:41010302002363
Copyright © 2010-2023 All Rights Reserved. 地址:河南自由贸易区开封片区经济开发区宋城路122号