当Nvidia 在 2019 年 3 月宣布以 69 亿美元收购 Mellanox Technologies 时,每个人都花了很多时间思考两家公司之间的协同效应,以及网络将如何成为运行 HPC 和 AI 的分布式系统中越来越重要的一部分工作量。据我们所知,并非所有人都认为 Nvidia 创建的用于将其 GPU 相互连接并扩展其系统的模拟信号电路是该交易的战略部分。
但是,事实证明,他们是。更具体地说,Nvidia 在设计串行器/解串器电路方面的专业知识 - 芯片的一部分,它采用并行数据流并将其转换为适合通过网络发送的串行数据流 - 在新的 Spectrum-4 800 中发挥了重要作用Nvidia(前身为 Mellanox)最近在 GTC 会议上宣布的 GB/sec 以太网交换机。
早在 2016 年,当我们看到用于数据中心的“Pascal”GP100 GPU 上的 20 Gb/秒 NVLink 端口时,我们就知道 Nvidia 在 SerDes 方面非常出色,而且我们真的看到该公司在泄露 NVSwitch 内存时对 SerDes 是认真的基于“Volta”GV100 和“Ampere”GA100 GPU 的 DGX 系列系统的核心区域网络交换机,以及用于 GPU 的独立式多层 NVLink 4.0 内存互连,将在未来 DGX H100 中使用基于“Hopper”GH100 GPU 的系统是极高带宽和低延迟的开关,我们在此处详细讨论过,其电路可与 Mellanox、Broadcom、Marvell 和其他公司所能承受的任何产品相媲美。
事实上,Nvidia 开发的 SerDes 专业知识对 Mellanox 团队非常有价值,这也是为什么使用 Spectrum-4 交换机,该公司正在从 Spectrum-12.8 Tb/秒的总带宽跃升的原因之一- 3 ASIC 于 2020 年 3 月直接发布了 25.6 Tb/秒的设备,许多人一直期待 51.2 Tb/秒的 Spectrum-4 ASIC。
“在数字方面,借助数据包处理引擎,我想说的是,Mellanox 在市场上遥遥领先,”Nvidia 以太网交换机和 DPU 营销副总裁 Kevin Deierling 表示。“我认为我们拥有世界上最好的数字交换机。现在,作为 Nvidia 的一部分,我们正在利用来自 Nvidia 的世界上最好的模拟 SerDes。模拟电路通常是到达芯片的最重要的项目,您必须确保它能够正常工作。数据包引擎,骰子的数字部分,如果你模拟了它,那就是它的行为方式,就是这样。对于模拟,它既是一门艺术,也是一门科学。”
Deierling 还没有准备好详细说明在 Spectrum-4 ASIC 中使用了 Nvidia 的哪些 SerDes,但他确实告诉我们,SerDes 的性能和功率以及光收发器的节省将成为Spectrum-4 的故事,Nvidia 将在今年晚些时候向我们透露,在 ASIC 及其同伴 ConnectX-7 SmartNIC 和 BlueField-3 DPU 全部批量发货之前进行更深入的研究。我们强烈怀疑 S[pectrum-4 中的相同 SerDes 用于 NVSwitch 3 和 NVLink Switch 1 芯片,但我们还不能证明这一点。
我们可以告诉你的是,Spectrum-4 ASIC 实际上是集成的小芯片的集合,Deierling 不敢说。据我们所知,数字封装和环绕它的通信 SerDes 都是在同一个 4 纳米 4N 工艺中实现的,该工艺来自代工合作伙伴台积电,也用于蚀刻新的“Hopper”GH100显卡。有趣的是,Hopper GPU 是具有 800 亿个晶体管的单片芯片,而 Spectrum-4 ASIC 具有小芯片架构,并且在整个复合体中具有 1000 亿个晶体管。
在未来,可以合理地预期数据包引擎将缩小到更小的晶体管几何尺寸,但考虑到使 SerDes 更小并不总是产生更好的性能,未来几代的 Spectrum ASIC 复合体的 SerDes 块将保持在4N过程。AMD 在其 Epyc 处理器复合体中的 I/O 集线器上也做了同样的事情。对于“Milan”Epyc 7003,I/O 集线器采用 GlobalFoundries 12 纳米工艺蚀刻,但与之相连的计算核心芯片采用台积电 7 纳米工艺蚀刻。
Spectrum-4 ASIC 核心的数据包引擎每秒可处理 376 亿个数据包,是Spectrum-2 每秒可处理 95.2 亿个数据包的 4 倍,而我们估计 Spectrum-每秒可处理约 190 亿个数据包。 3或大约 2 倍的吞吐量。数据包处理速率并不总是与交换机系列的带宽增长同步增长,Mellanox 一直试图在这一指标上击败竞争对手。Spectrum-3 芯片是采用 TSMC 16 纳米工艺蚀刻的单片芯片。
与之前的 Spectrum ASIC 一样,Spectrum-4 ASIC 复合体上的 SerDes 可以组合成 2、4 或 8 个组,以创建给定带宽的以太网端口——在本例中为 200 Gb/秒、400 Gb/秒、和 800 Gb/秒,因为通道速度为 100 Gb/秒(即在去除编码开销之后)。原生信号传输速率为 50 Gb/秒,并且采用 PAM-4 脉冲幅度调制编码,允许每个信号通过两个比特,有效通道速度达到 100 Gb/秒。因此,凭借 2、4 或 8 个通道,Spectrum 4 芯片可以以 200 Gb/秒的速度驱动 256 个端口,以 400 Gb/秒的速度驱动 128 个端口,以 800 Gb/秒的速度驱动 64 个端口——后者对于内部的数据中心互连很重要可以通过以太网线跨越的区域。
对于那些数据中心互连(或所谓的 DCI)用例来说,同样重要的是 Spectrum-4 ASIC 内置了 MACsec 加密,这意味着传输中的数据可以以四分之一的线路速率(或者可能更精确,在以 800 Gb/秒运行的端口的四分之一或以 200 Gb/秒运行的所有端口上)。超大规模和云构建者中用于 DCI 应用程序的交换机的平均加密速率约为 4 Tb/秒,因此是该速率的 3 倍多。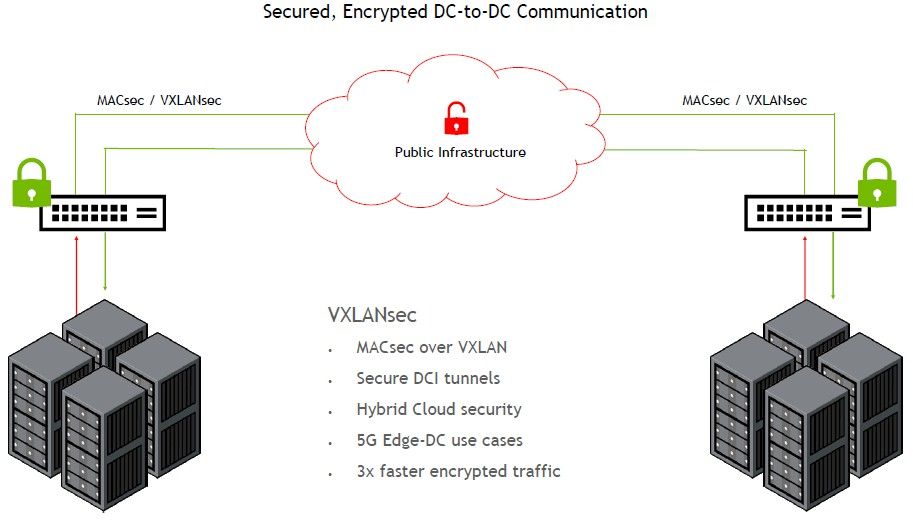
看到 Nvidia 可以将 Spectrum-4 ASIC 分解为以 100 Gb/秒的速度运行 512 个端口的用例,并考虑在 Clos all-to-all 拓扑脊/叶中有多少个交换机跃点,这将是非常有趣的网络可以被淘汰。但我们怀疑,如果许多客户迁移到服务器上的 200 Gb/秒端口,他们会对 12:1 压缩感到满意。像这样: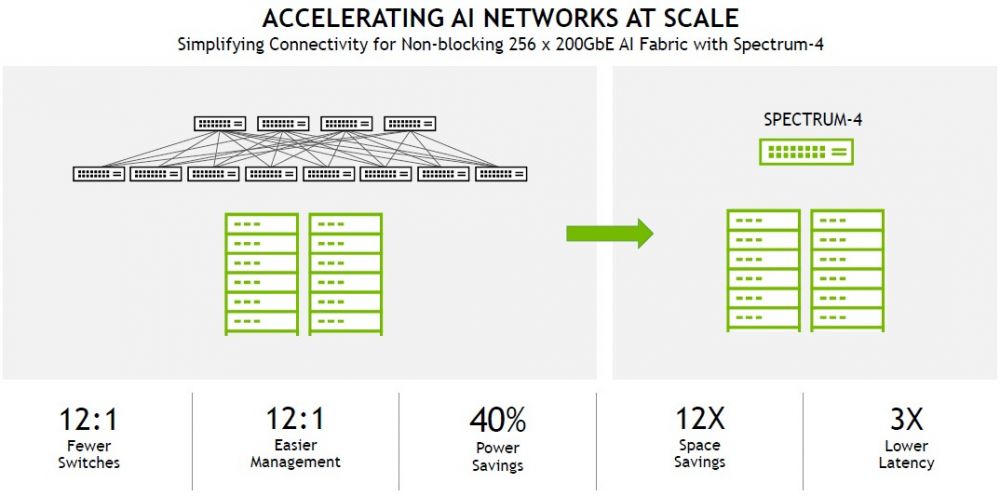
使用 Spectrum-4 连接 256 台服务器意味着所有机器彼此相距一跳。要将相同的 256 台服务器与 Spectrum-3 交换机连接起来,将需要 12 倍的交换机来构成脊/叶网络,并且在交换机结构上的服务器之间平均需要三跳,从而将网络延迟增加 3 倍。
Spectrum-4 芯片和交换机的定价尚未确定,但 Nvidia 将像 Mellanox 一样销售完整的交换机和 ASIC。定价的经验法则是,对于任何给定的代际跳跃,每个端口的带宽增加 2 倍,每个端口的成本增加 1.5 倍至 1.6 倍。看起来 Nvidia 正在跳过 25.6 Tb/秒的 ASIC 一代,这应该意味着 800 Gb/秒的端口应该运行在 1,800 到 2,000 美元左右,这与 2015 年 100 Gb/秒端口开始时的 100 Gb /sec波首先开始构建。这也与 400 Gb/秒端口目前以接近 1,000 美元的价格运行的事实一致。
Nvidia Spectrum-4 交换机推出的最后一项重大新技术是自适应路由和使用 RoCE 协议改进服务器节点之间的直接内存访问,这是对 RDMA 直接内存访问的重复,它提供了 InfiniBand(Mellanox 和现在Nvidia冠军)如此低的延迟。
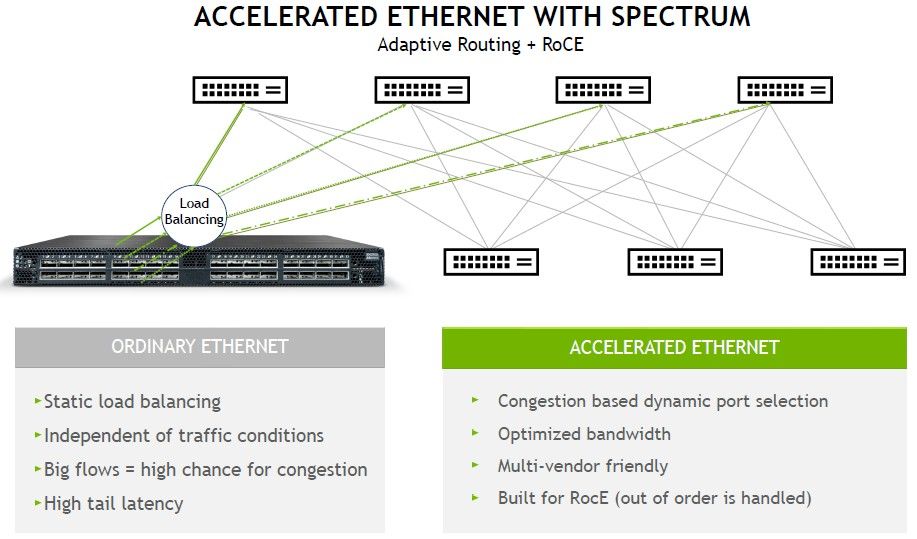
自适应路由很重要,特别是对于 AI 训练工作负载和分布式数据库——Mellanox 在那些不想使用 InfiniBand 的人中使用 Spectrum ASIC 获得牵引力的地方。
“我们已经了解了很多关于人工智能和数据库的知识,”Deierling 解释道。“在传统的网络模型中,你有大量的 CPU 线程和大量要连接的套接字,并且网络上有大量的流量。在这里,您可以使用静态路由,例如 Equal Cost Mutli-Path 或 ECMP 路由。一切正常,因为这些是鼠标流,应用程序确实不需要交换大量数据。但是对于 AI 和数据库工作负载,它们确实如此,并且您会得到这些大流量,而对于大流量,您需要更加小心。我们确定大流量发生在哪里,并确保不会在同一链路上发送太多流量,因此我们实现了最佳带宽,因此这些巨大的工作负载可以大规模运行。”
Deierling 表示,这种自适应路由技术源自 InfiniBand 自己的自适应路由,它从一开始就拥有这种路由技术,并且之所以成为可能,是因为 InfiniBand 是“在它很酷之前是软件定义的网络”,并且正在被添加到其以太网产品中两家超大规模企业和云建设者的要求。我们强烈怀疑其中之一是微软,它是 Nvidia InfiniBand 的大客户,但另一个可能是谷歌。
这就是我们这么认为的原因。Spectrum-4 交换机中的另一个新功能是一种称为超精确计时的功能,它实现了精确时间协议,这在大规模分布式数据库中是必需的。使用网络时间协议,它已经在网络中使用了 35 年,您能做的最好的事情是大约 10 毫秒到大约 1 毫秒的同步。任何需要比这更细粒度的东西都需要其他一些计时机制——例如,谷歌在其数据中心使用原子钟来同步其 Spanner 分布式数据库中的数据读写. 借助 Spectrum-4 ASIC 中的超精确计时功能,数据流可以以低至数十纳秒的精度进行标记,这足以跟踪对数据库的写入顺序并确保读取数据部分在写入完成后完成。
这种基于网络的细粒度数据同步对于所有使用或销售大规模数据库的超大规模企业和云建设者以及在基础设施上运行它们或将它们用作这些超大规模企业和云服务的客户来说都是必要的建设者。但看看英伟达能否赢得与谷歌的网络交易将会很有趣。
工作时间:早上9:00-下午6:30
河南快米云网络科技有限公司
 公安备案编号:41010302002363
公安备案编号:41010302002363
Copyright © 2010-2023 All Rights Reserved. 地址:河南自由贸易区开封片区经济开发区宋城路122号

